At the IRMS conference in Brighton in May I had conversations with several vendors of manage-in-place records management tools about how they went about ensuring that their products could connect with the applications in day-to-day use within organisations
The importance of APIs (application programming interfaces)
In order for the manage-in-place tool to work it needs to have a ‘connector’ to each content repository that it wishes to govern.
The connectors are typically built to use the API (application programming interface) of the content repository. The API exposes a subset of the content repository’s functionality. It specifies how any authorised external application (in this case a manage-in-place tool) can issue commands to the content repository.
Some of the things that a records manager might want their manage-in-place tool to do inside the various content repositories of your organisation include:
- adding metadata to a document or aggregation of documents
- linking an aggregation of documents to a node in a records classification
- preventing editing or deletion of a document or aggregations of documents
- linking a retention rule to a piece of content or an aggregation of content
The beauty of the concept of an API is that the two applications can interact with each other without you having to customise either application. It does not matter if the two applications are written in entirely different programming languages. Nor does it matter if one or both of the applications are based in the cloud.
In theory:
- you could replace your manage-in-place tool with a new manage-in-place tool from a different vendor, and none of the content repositories need notice any difference (provided that the new manage-in-place tool carried on issuing the same commands to their API)
- you could replace a content repository with a successor repository from a different vendor without the manage-in-place tool noticing any difference (provided that the new content repository offered a similar API that enabled them to make the same commands)
In practice each vendor constructs the API for their content repository differently, and this creates two challenges for the makers of manage-in-place tools
1) they have to construct a different connector for each different vendor’s content repository. Two of the manage-in-place providers I spoke to at the conference (RSD and IBM) both provided connectors to over 50 different commonly used content repositories.
2) some APIs are better than others. Some applications expose more functionality through their API than other applications, and hence let the manage-in-place tool do more things to their content. One example cited was that the manage-in-place tool can get some document management systems to display the organisation’s records classification (fileplan), so that users of the document management system can link or drag and drop content to the appropriate node in the classification. Other document management system do not have that functionality exposed in their API.
CMIS (Content management interoperability services)
CMIS is a specification that aims to overcome the first of these two problems. The specification was drawn up by a coalition of vendors in the ECM space under the auspices of the OASIS Technical committee.
The idea is that vendors add a CMIS layer to their applications. Just like an API, the CMIS layer exposes a subset of the functionality of the native application, so that an external application can make use of that functionality. The difference is that whereas each vendor’s API is constructed and expressed in a different way, a CMIS layer is standardised. This means that a similar function (for example ‘add a document’) would be expressed in the same way in the CMIS layer of each vendor’s products.
A mange-in-place tool vendor could choose to build connectors to the CMIS layers of content repositories, rather than through the API. In theory this saves a manage-in-place vendor from building seperate connectors for every different type of content repository they want their product to be able to govern.
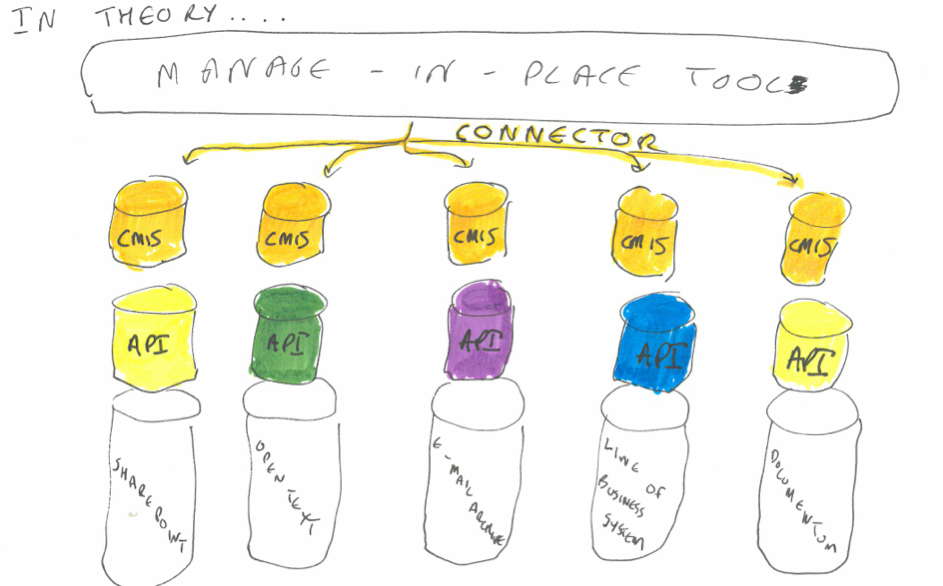
In practice the vendors of the manage-in-place tools that I spoke to told me that they prefer to write connectors that use the API of each application, rather than the CMIS layer. This is simply because most repositories expose more functionality through their API than through their CMIS layer.

CMIS and records management
The disadvantage of CMIS being writtten by vendors is that a coalition of vendors have to agree for functionality to be put into the specification. They have tried to capture concepts and functions that are common to all or most existing repositories. Functionality such as records management, which some repositories have and some don’t, has not received prominent treatment in CMIS. The first version of CMIS had concepts such as a document, and a folder, but it did not support retention rules, nor a records classification/fileplan (although it did have the concept of a folder structure).
The latest version of CMIS (1.1) does have retention functionality in for the first time. But that has not pleased all of the vendors. Jeff Potts, of Alfresco wrote this in his blogpost announcing the approval of CMIS 1.1
This new feature allows you to set retention periods for a piece of content or place a legal hold on content through the CMIS 1.1 API. This is useful in compliance solutions like Records Management (RM). Honestly, I am not a big fan of this feature. It seems too specific to a particular domain (RM) and I think CMIS should be more general. If you are going to start adding RM features into the spec, why not add Web Content Management (WCM) features as well? And Digital Asset Management (DAM) and so on? I’m sure it is useful, I just don’t think it belongs in the spec.
This is the dilemma for CMIS:
- if they do not give full coverage of sets of functionality such as records management then manage-in-place tools will bypass the layer and just use the APIs of the content repositories.
- the more detailed and precise their definition of records management functionality is, the harder it is to get the coalition of vendors to agree on it
From a records mangaement point of view what we want out of CMIS (or any other standard in the API space) is to set out a minimum set of records management functionality that the API of every business systems sbould have.
In theory, if CMIS specified a set of API commands that would expose the functionality needed by one or more of the current electronic records management specifications, then vendors would never have to re-architect their product to meet that electronic records management specification, All they would need to do is expose the relevant functionality in their CMIS layers and let the manage-in-place tools use that functionality to govern the content they hold.
Of course this would not solve all of our problems – one of the biggest content repositories in most organisations are simple shared network drives, that don’t have an API (never mind a CMIS layer!).

Great blog post James. You perfectly understood the challenges of managing records in-place. As mentioned by John Garde one should not forget that most records will never leave their system of origin (https://thinkingrecords.files.wordpress.com/2012/07/362-jongarde.jpeg). I would even say that records should leave in the system which makes the most sense for them at a given point in time. With the deluge of information we face and the multiplication of content-enabled applications the strategy consisting to centralize all archives into one single system is doomed to fail. Simply because records now exist all over the place from email server to sharepoint not including social media or new generation of cloud object stores.
Moreover content technologies evolve over time and records needs to be properly moved from one system to another while ensuring a continuous and defensible audit history. Transferring records from one Record Management System to another is one solution but it is much simpler and cost-effective for an organization to add a new connector to a repository-agnostic ILM system and ensure a proper tracking of all records wherever they currently resides rather than having to develop complex record export/import mechanisms (transferring records to National Archives is something most private companies do not have to manage… and even for governmental purpose a distributed system would make in my humble opinion much more sense).
Finally one of the key missions of ILM system is also to manage content orchestration and strategic content move over time. A Corporate Record Manager may for example decide to only keep active records for 3 years in his MS SharePoint implementation and to automatically move them to a low cost cloud repository such as AWS S3 or AWS Glacier for the rest of their life. Information Lifecycles are today much more complex than retention and disposition rules only.
It makes then perfect sense to fully decouple Information Lifecycle Management from the content storage system and to implement a truly federated approach.
Once we agree on this vision we need to distinct two fundamentally different approaches:
– Federated Record Management
– Delegated Record Management
The former unifies all the key functional capabilities required by a Record Management System (File Plans; Time and Event-based retention rules; Record Event History; Lifecycle-oriented business processes and workflows; Metadata Management, etc.). Such a system does not require a content interoperability protocol as complex as CMIS to start governing content in-place but only a small sub-set of it. In fact this system only needs to be able to access to the content (Content UID + Access method), delete it and hold/freeze it (notion of content immutability) to enforce and execute a standard information lifecycle. All the rest could be done from within the Federate RM system. Of course accessing to more advanced methods such as being able to search for content (federated search or record discovery kind of capabilities), store new items (e.g: required if the Record Manager wants to move content from one system to another) or accessing to the repository audit trails could be good plus. Most repositories out there, including shared drives (e.g: CIFS-SMB Protocol) offer however support for basic content access and deletion. Getting a proper level of immutability in-place is usually the most challenging option and may sometime requires some workaround such as dynamically modifying the content ACL. CMIS 1.1 supports now for example the Hold feature and can be used as a perfect example of a generic governance connector. IMHO I even think that we could start working on defining a sub-set of CMIS 1.1 that a repository will have to implement to support 3rd party ILM vendors. This could be a perfect fit for a “MoReq Client API” which would be the simplest as possible to cover as many repository vendors as possible. To be discussed.
The Delegated RM approach consists in defining all information policies from a centralized system and to propagate them into each content repository that the organization needs to support. The content repository is then in charge of applying the lifecycle on the governed content items. Most advanced content repositories out there now support one form or another of an information policy. At first glance it would then make perfect sense to only prepopulate these policies across all content repositories. The problem is that rapidly information policies become dependent of each repository or need to implement with a lowest common denominator approach (e.g: time-based retention support only). And the organization completely lose all options to move and orchestrate content over its lifecycle as no system knows any more where all records are really located. The advantages are clearly in the performance and scalability of such an approach as you can trust the distant repository to execute a certain number of native actions (e.g: retain for X years and delete afterwards). IMHO this approach is probably better to implement simpler “Information Lifecycle Management” tasks (e.g: apply unified information policies on non-records such as transient content items) rather than on real and formal records.
Of course hybrid scenarios are always possible.
What is sure is that there is no simple information discovery and lifecycle management API out there that could both serve to legal eDiscovery and ILM vendors. CMIS is nice but certainly too complex for some types of content repositories which do not ambition to become a full-fledge ECM System (AWS S3 will never support CMIS – does it necessarily mean that organization can not store records in there? Does it also mean that organization will not push Amazon to support better eDiscovery, Legal Hold and ILM capabilities? Certainly not). So there is certainly the need to define a very simple ILM API which could serve as a worldwide standard and which could be based on a sub-set of either CMIS 1.1 or CDMI (e.g: http://cdmi.sniacloud.com/cdmi_spec/17-retention_and_hold_management/17-retention_and_hold_management.htm) or both. Such an ILM API will only require the content storage systems to implement those minimum functions required to unify information policies across all content repositories. The KISS approach is usually the one that best works!
Just somethoughts. Thanks again for the great blog post.
Best Regards
Stéphane Croisier
Product Manager @ RSD.
This all sounds vaguely familiar! 😉 Well done James, good summation, glad we ad a chance to speak at IRMS.
I think that in reality as CMIS matures it will inevitably expose more and more of the underlying functionality of the repositories, making the idea of a unified ILG/ILM layer less utopian.
In the meantime however, we need to consider that the majority of organisations are in the File Server end of the spectrum. For them, in-place retention management is probably even more important, because the idea of migrating *all* of that data to a place where it can be catalogued and purged is a non-starter. Basic in-place disposition, gives them an opportunity to tackle their “fear of the unknown” and at least start applying migration and retention strategies (within the appropriate repositories) to a much more manageable sub-set than they are handling now.
Regards
George