To understand Microsoft’s strategy for document management in Office 365 it is more instructive to look at what they are doing with Delve, MS Teams and Project Cortex than it is to look at what they are doing with SharePoint.
The move to the cloud has had a massive impact on document management, despite the fact that document management systems (such as SharePoint) have changed relatively little.
What has changed is that cloud suites such as Office 365 and GSuite have created a much closer relationship between document management systems and the other corporate systems holding ‘unstructured’ data such as email systems, fileshares and IM/chat. This closer relationship is fuelling developments in the AI capabilities that the big cloud providers are including in their offerings. Project Cortex, set to come to Office 365 during 2020, is the latest example of an AI capability that is built upon an ability to map the interconnections between content in the document management system and communication behaviour in email and chat.

SharePoint in the on-premise era
In its on-premise days SharePoint was in many ways a typical corporate document management system. It was the type of system in which:
- colleagues were expected to upload documents, add metadata and place documents within some kind of overarching corporate structure.
- information managers would work to optimise the information architecture and in particular the search capability, the metadata schema and the structure of the system.
- retention rules would be held and applied to content.
It was the type of system that an organisation’s might call their ‘corporate records system’ on the grounds that documents within the system are likely to have better metadata and be better governed, than documents held elsewhere.
SharePoint in the cloud era
In Office 365 SharePoint’s role is evolving differently. Its essential role is to provide document management services (through its document libraries) and (small scale) data management services (through its lists) to the other applications in the Office 365 family, and in particular to MS Teams.
SharePoint can still be configured to ask users to add metadata to documents, but users have three quicker alternatives to get a document into a document library:
- If the document library is synched with their Explorer they can drag and drop a document from anywhere on their computer drive into the document library.
- They could simply post the document to a channel in their Team in MS Teams which will place it in the document library in the SharePoint Team Site associated with the Office 365 group that underpins their Team.
- They could post it to a private channel in a Team which would cause the document to be stored in a document library within a site collection dedicated to that private channel.
SharePoint can and should still be given a logical corporate structure but MS Teams may start to reduce the coherence of this structure. Every new Team in MS Teams has to be linked to an Office 365 group. If no group exists for the Team then a new group has to be created. The creation of a new Office 365 Group provisions a SharePoint site in order to store the documents sent through the channels of that Team. Every time a private channel is created in that Team it will create another new SharePoint site of its own.
SharePoint still has a powerful Enterprise search centre within it, but it is rivalled by Delve, a personalised search tool that sits within Office 365 but outside SharePoint. Delve searches not just documents in SharePoint but also in One Drive for Business and even attachments to emails.
SharePoint can still be configured to apply retention rules to its own content through policies applied to content types or directly to libraries. However a simpler and more powerful way of applying retention rules to content in SharePoint is provided outside SharePoint, in the retention menu of the Office 365 Security and Compliance Centre. This retention menu is equally effective at applying retention rules (via Office 365 retention policies and/or labels) to SharePoint sites and libraries, Exchange email accounts, Teams, Teams chat users and other aggregations within the Office 365 environment.
Microsoft’s attitude to Metadata
Microsoft’s Office 365 is a juggernaut. It is evergreen software which means that it has regular upgrades that take effect immediately. It faces strong competitive pressures from another giant (Google). It needs to gain and hold a mass global customer base in order to achieve the economies of scale that cloud computing business models depend on.
Information architects of one sort or another are part of the ecosystem of Office 365. Like any other part of the Office 365 ecosystem information architects are impacted by shifts, advances and changes in the capabilities of the evergreen, everchanging Office 365. Suppliers in the Office 365 ecosystem look for gaps in the offering. They don’t know how long a particular gap will last, but they do know that there will always be a gap, because Microsoft are trying to satisfy the needs of a mass market, not the needs of that percentage of the market that have particularly strong needs in a particular area (governance, information architecture, records management etc.).
The niche that SharePoint information architects have hitherto occupied in the Office 365 environment will be changed (but not diminished) by Microsoft’s strategy of promoting:
- Teams as the interface and gateway to SharePoint;
- Delve as the main search tool for Office 365;
- the forthcoming Project Cortex as the main knowledge extraction tool;
- the Security and Compliance centre as the main locus of retention policies.
Microsoft’s need to win and keep a mass customer base means that they need document management to work without information architecture specialists because there are not enough information architecture specialists to help more than a minority of their customers.
Microsoft’s plans for SharePoint to be a background rather than a foreground element in Office 365 will take time to run their course, and that gives us time to think through what the next gap will be. What will be the gap for information architects after SharePoint has been reduced to a back end library and list holder for Teams, Delve, Cortex and the Microsoft Graph?
In order to come up with a proposed answer to this question this post will explore in a little bit more detail how and why Microsoft’s document management model has changed between the stand alone on premise SharePoint and SharePoint Online which is embedded in Office 365.
The on-premise corporate document management system model
On-premise corporate document management systems, up to and including the on premise SharePoint, were built on the assumption that a corporate document management system could stand separately from the systems (including email systems) that transported documents from person to person.
This assumption had been based on the idea that good metadata about a document would be captured at the point that it was entered into the system, and updated at any subsequent revision. This metadata would provide enough context about the documents held in the system to render superfluous any medium or long term retention of the messages that accompanied those documents as they were conveyed from sender to recipient(s).
The model depended on a very good information architecture to ensure that:
- every person (or machine) uploading a document to the system was faced with a set of relevant metadata fields;
- these metadata fields were backed, where necessary, by controlled vocabularies, that present a set of coherent and contextually relevant choices for metadata values.
The problem with this model is that it is not feasible to design an information architecture for a corporate wide stand alone document management system that describes documents in a way that means that documents across all of an organisation’s different activities are understandable and manageable. You can achieve this for some parts of the system, but not for the whole system.
There are two ways you can set up an information architecture: top down or bottom up. Neither approach works on a corporate wide scale:
- In the top down approach you define a corporate controlled vocabulary for every metadata field that needs one. The trouble with this is that for any one individual user the vast majority of the values of those vocabularies would be irrelevant, and they would have to wade through all these irrelevant values every time they wanted to upload a document to the system.
- In the bottom up approach you define locally specific vocabularies. SharePoint was and is particularly good for this. For any particular document library you can define vocabularies tailored specifically to the content being put into that libraries. However then you get the problem that an implementation team in a medium or large organisation has not got the time to define locally-specific metadata for every single area of the business.
There is a way by which this information architecture problem can be solved. It involves:
- mapping different controlled vocabularies to each other, so that the choice of a metadata value in one field removes any conflicting values in the controlled vocabularies of any other metadata field.
- mapping metadata fields to a users role, so that any values in a controlled vocabulary that are irrelevant to the user are removed
This is already starting to look like a graph – like the Facebook social graph that drives search in Facebook, the Google Knowledge Graph that is built into Google Search and the Microsoft graph which is the enterprise social graph that underpins Delve and Project Cortex in Office 365.
Enterprise social graphs
An enterprise social graph is an established set of connections between:
- information objects (such as documents)
- the people who interact with those documents;
- the actions those people perform on those documents (saving them, sending them, revising them etc.)
- the topics/entities (such as policy issues, projects, countries, regions, organisations, disciplines etc. etc.) discussed in those documents.
The deployment of a graph significantly reduces the reliance of a system on metadata added by an end user (or machine) at the time of the upload of a document into a system. The mere fact that a particular end user has uploaded a document to a particular location in a system is already connecting that document to the graph. The graph connects the document to other people, topics and entities connected with the person who uploaded the document.
Graphs consist of nodes (people, objects and topics) and edges (the relationships between the nodes).
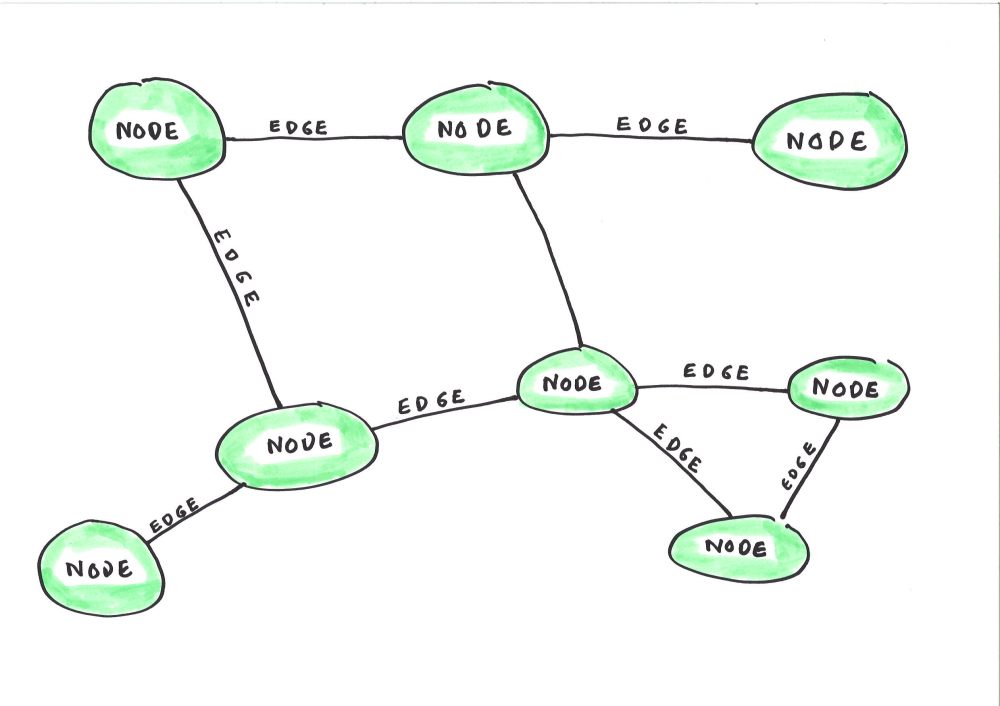
The concept of the graph has enormous potential in information architecture. You could narrow down the range of permitted values for any metadata field for any document any individual contributes to a system just by ensuring that the system knows what role they occupy at the time they upload the document.
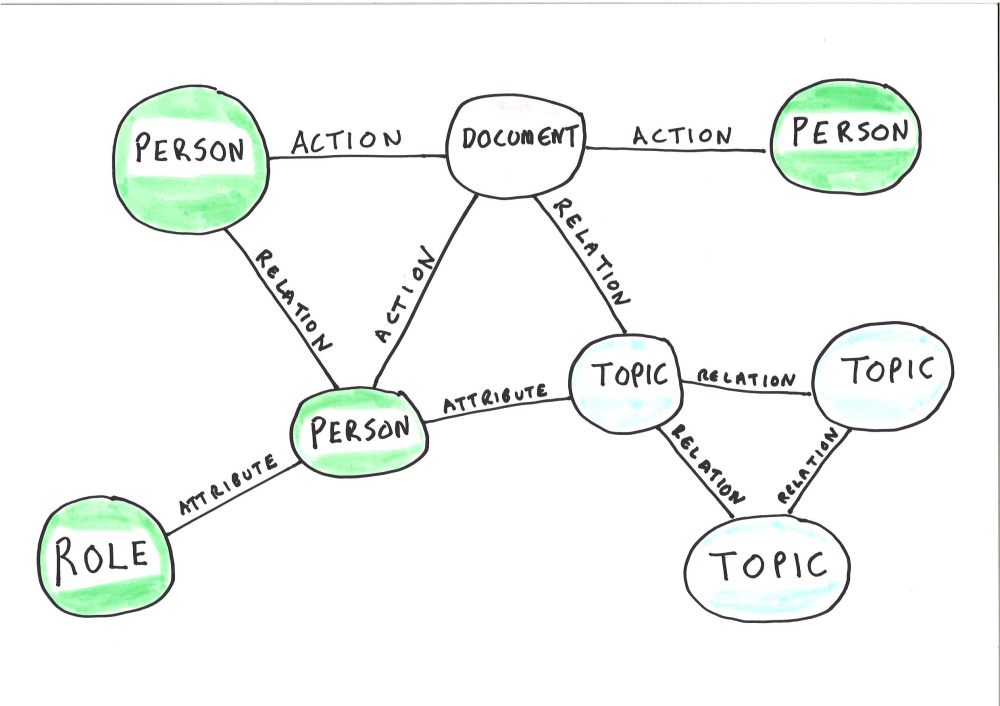
This pathway towards smart metadata also takes us away from the idea of the document management system as a stand alone system.
If we see a document management system as a world unto itself we will never be able to capture accurate enough metadata to understand the documents in the system. Better to start with the idea that the documents that an individual creates are just one manifestation of their work, and are interrelated and interdependent with other manifestations of their work such as their correspondence, their chats, and their contributions to various line of business databases.
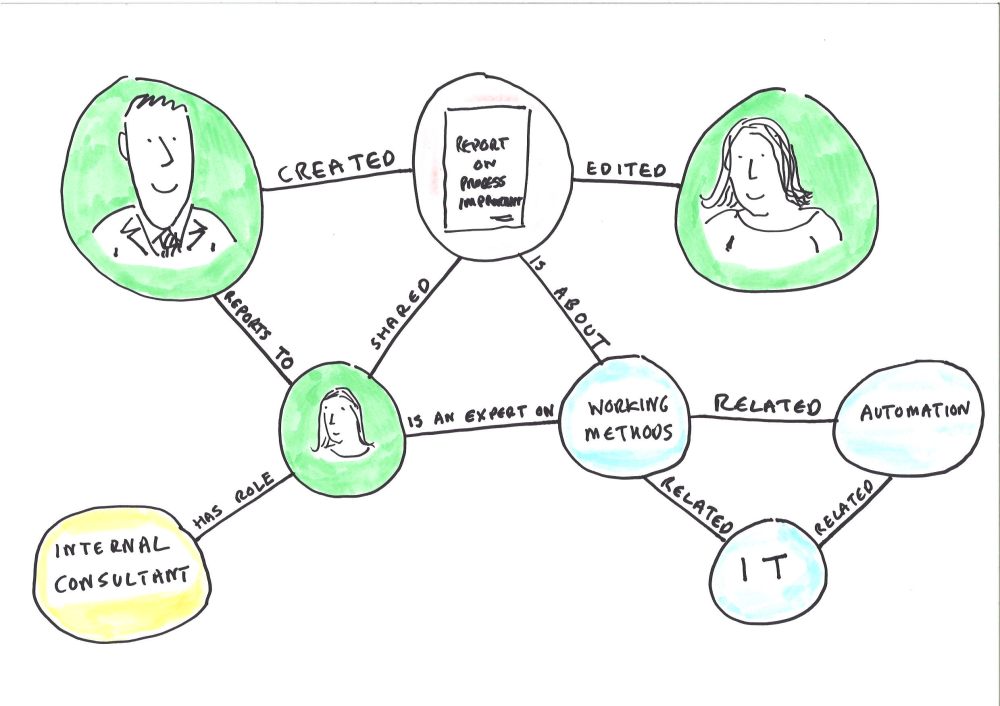
We can also distinguish between a knowledge graph, which is built out of what an organisation formally knows, and a social graph which is built out of how people in an organisation behave in information systems. The cloud providers have started by providing us with a social graph. Over time that social graph may improve to become more like a knowledge graph, and we will see below when we look at Project Cortex that Microsoft are taking some steps in that direction. But there is still some way to go before the enterprise social graph provided by Microsoft has the precision of an ideal knowledge graph. Note the word ‘ideal’ in that sentence: I have never worked in an organisation that has managed to get a knowledge graph (as opposed to a social graph) up and functioning.
The nature of an ideal knowledge graph will vary from organisation to organisation. An engineering firm needs a different type of graph from a ministry of foreign affairs which needs a different type of graph from a bank etc. etc.
In an engineering firm an ideal knowledge graph would connect:
- the people that are employed;
- the projects that are being carried out by the company;
- the systems that are being designed, manufactured, installed and maintained;
- the structures that are being designed and built,
- the engineering disciplines that are involved.
These different datasets and vocabularies can be mapped to each other in a graph independently of any document. Once a graph is constructed a document can be mapped to any one of these features and the range of possible values for all the other features should correspondingly reduce.
In a foreign ministry an ideal knowledge graph would connect
- the people that are employed
- the location they are based in
- their generic role (desk officer, subject expert, ambassador etc.);
- the country(ies) that they deal with
- the people they work closely with
- the multilateral fora that are participated in
- thematic topics
- types of agreements/treaties.
Again these can be mapped independently of any documents. Staff can be mapped to the countries they are based in/follow or to the thematic topic they work on.
The notion of the graph (whether a knowledge graph or a social graph or a blend of the two) brings home the fact that the data, document and messaging systems of an organisation are all interdependent. The graph becomes more powerful from a machine learning and search point of view if it is kept nourished with the events that take place in different systems. When a person emails a document to another person this either reinforces or re-calibrates the graph’s perception of who that person works with and what projects, topics or themes they are working on.
Information architects will still need to pay attention to the configuration of particular systems, and corporate document management systems bring with them more configuration choices than any other information system I can think of. They should however pay equal attention to the configuration of the enterprise social graph that the document management system, in common with the other systems of the organisation, will both contribute to and draw from.
The next section looks at why both end users and Microsoft have tended to move away from user added metadata in SharePoint.
SharePoint and user added metadata
In a recent IRMS podcast Andrew Warland reported that an organisation he worked with synched their SharePoint document libraries with Explorer, and that subsequently most users seemed to prefer accessing their SharePoint documents through the ‘Explorer View’ rather than through the browser.
This preference for using the Explorer view over the browser view is counter intuitive. The browser view provides the full visual experience and the full functionality of SharePoint, whereas the Explorer view in effect reduces SharePoint to one big shared drive. But it is understandable when you think of the relationship between functionality and simplicity. Those purchasing and configuring information systems tend to want to maximise the functionality of the system they buy/implement. Those using it tend to want to maximise the simplicity. These things are in tension – the more powerful the functionality the more complex the choices presented to end users. The simplest two things a document management system must do is allow users to add documents and allow them to view documents: Explorer view supports both of these tasks and nothing else.
At this point I will add an important caveat. Andrew didn’t say that all end users preferred the explorer view. Some sections of the organisation had more sophisticated document library set ups that they valued, and were prepared to keep adding and using the metadata. But if the hypothesis advanced at the start of this post is correct then it is not feasible to configure targeted metadata fields with context specific controlled vocabularies for every team in an organisation when rolling out a stand alone document management system.
Graham Snow pointed out in this tweet that one disadvantage of synching document libraries with Explorer is that when a user adds a document they are not prompted to add any metadata to it. This raises two questions:
- why are Microsoft giving a get out to the addition of metadata when we know how important metadata is to retrieval?
- why are so many end-users seemingly uninterested in adding metadata when they would, in theory, be the biggest beneficiaries of that metadata?
Let us start by confirming that Metadata indeed is important. In order to understand any particular version of any particular document you need to understand three things:
- who was it shared with?
- when was it shared with them?
- why was it shared with them?
This provides a clue as to why many end-users don’t tend to add metadata to documents. If a document was shared via email then the end-user has the metadata that answers those three crucial questions, in the form of an email sitting in their email account. Their email account will have a record of who they shared it with (the recipient of the email), when (the date of the email) and why (the message of the email). One question we might ask ourselves is why have we not sought to routinely add to the metadata of each document the details which we could scrape from the email system when it is sent as an attachment? These details include the date the document was sent, the identity of the sender and the identity(ies) of the recipient(s).
The Microsoft graph
Microsoft are trying to make Office 365 more than simply a conglomeration of stand alone applications. They are trying to integrate and interrelate One Drive, Outlook, Teams, SharePoint and Exchange, to provide common experiences across these tools which are they prefer to call separate Office 365 ‘workloads’ rather than separate applications. This effort to drive increased integration is based on two main cross Office 365 developments: an Office 365 wide API (called Microsoft Graph API) and an enterprise social graph (called the Mircosoft Graph).
The Microsoft Graph API provides a common API to all the workloads in Office 365. This enables developers (and Microsoft themselves) to build applications that draw on content held and events that happen in any of the Office 365 workloads.
Microsoft Graph is an enterprise social graph that is nourished by the ‘signals’ of events that happen anywhere in Office 365 (documents being uploaded to One Drive or SharePoint; documents being sent through Outlook or Teams; documents being edited, commented upon, liked, read, etc.). These signals are surfaced though the Microsoft Graph API.
Microsoft Graph was set up to map the connections between individual staff, the documents they interact with, and the colleagues they interact with. For most of its existence Microsoft graph has been more of a social graph than a knowledge graph.
The forthcoming project Cortex (announced at the Microsoft Ignite conference of November 2019) takes some steps in the direction of turning Microsoft Graph into a knowledge graph. It will create a new class of objects in the graph called ‘knowledge entities’. Knowledge entities are the topics and entities that Cortex finds mention of in the documents and messages that are uploaded to/exchanged within Office 365. Cortex will create these in the Microsoft Graph and link them to the document in which they are mentioned and the people that work with those documents.
Applications built on top of the Microsoft graph
The three most important new services that Microsoft has built within Office 365 since its inception are Delve, Microsoft Teams and Project Cortex. All three of these services are meant to act as windows into the other workloads of Office 365. They are all built on top of the Microsoft 365 graph, and they provide signposts as to how Microsoft wants to see Office 365 go and how it sees the future of document management.
MS Teams, Delve, Cortex and the Microsoft Graph are eroding the barriers between the document management system (SharePoint), the fileshare (One Drive for Business), the email system (Outlook and Exchange) and the chat system (Teams).
MS Teams
Teams is primarily a chat client. But it is a chat client that stores any documents sent through it in either:
- SharePoint document libraries (if the message is sent through a Teams channel or private channel) or
- One Drive for Business (Microsoft’s cloud equivalent of a fileshare) if the document is sent through a chat.
Delve
Delve uses Microsoft Graph to personalise, security trim, filter and rank search results obtained by the Office 365 search engine. Delve pushes these personalised results to individual users so that on their individual Delve page they see:
- a list of their own recent documents. This shows documents they have interacted with (sent, received, uploaded, edited, commented on, opened or liked) in Outlook Teams, One Drive or SharePoint.
- a list of documents they may be interested in. This is Delve acting as a recommendation engine and showing documents that the individual’s close colleagues have interacted with recently, and which relate to topics that the individual has been mentioning in their own documents.
Delve is working under certain constraints. It does not search the content of email messages, only the attachments. It does not recommend a documents to an individual who does not have access to that document.
There are some cases where Delve has surfaced information architecture issues. In an IRMS podcast discussion with Andrew Warland (which is currently being prepared for publication) Andrew told me how one organisation he came into contact with had imported all their shared drives into SharePoint without changing access permissions in any way. Each team’s shared drive went to a dedicated document library. The problem came when Delve started recommending documents. Sometimes Delve would recommend documents from one part of the team to people in a different part of the team, and sometimes the document creators were not pleased that the existence of those documents had been advertised to other colleagues.
The team asked Andrew whether they could switch off Delve. His response was that they could, but that switching off Delve (or removing the document library from the scope of Delve) would not tackle the root of the problem. The underlying problem was that the whole team had access to the document library that they were saving their documents into. He suggested splitting up the big document library into smaller document libraries so that access restrictions could be set that were better tailored to the work of different parts of the team.
Delve has taken baby steps to unlocking some of the knowledge locked in email systems that is normally only available to the individual email account holder (and to central compliance teams). Delve cannot search the content of messages but it can search the attachments of email messages and the metadata of who sent the attachment to whom.
Project Cortex
Project Cortex will take this one step further. It is a knowledge extraction tool. It seeks to identify items of information within the documents uploaded and the messages sent through Office 365. It is looking for the ‘nouns’ (think of the nodes on the graph) within the documents and the messages. The types of things it is looking for are the names of projects, organisations, issues etc. It seeks to create ‘topic cards’ and topic pages containing key pieces of information about these entities. A link to the topic card will appear whenever the project/organisation/issue etc. is mentioned in any Office 365 workload. Users will come across the link when they read or type the name of the entity into an email or a document. The topic cards and pages will also contain Cortex’s recommendations as to which colleagues are experts on the topic and which documents are relevant to the topic. Like Delve, Cortex will use Microsoft Graph to create these recommendations.
Project Cortex is tightly bound in with SharePoint. Its outputs manifest themselves in familiar SharePoint pages and libraries. Cortex uses the fact that SharePoint sites can be used to serve as an intranet to generate topic pages that function like Sharepoint intranet pages. Like SharePoint intranet pages you can add web parts to them, and they use document libraries to store and display documents. Project Cortex will populate the document library of a topic page with the documents that it mined to generate the information on the topic page. Colleagues who do not have access to those documents will not have access to the page.
The topic cards and pages will be editable (like wikipages). Project Cortex will link the topic pages for related topics together to form Knowledge Centres. These Knowledge centres will supplement (or rival) the organisation’s intranet.
SharePoint and machine added metadata
So far the knowledge centre/topic pages aspects of Project Cortex have got the most publicity, and they are the aspects that are likely to make the most immediate impression on end users. But I think and hope that the most useful aspects of Project Cortex will be two features that allow you to use machine learning to capture specified fields of metadata for a specified group of content in specified SharePoint document libraries.
- for structured documents (forms and other types of documents that follow a set template) Cortex provides a forms processing feature that allows you to identify particular elements form/template and map them to a metadata field. For any instance of that type of document the machine will enter the value found in that place in the document into the given metadata field.
- for unstructured documents you are able to train a machine learning tool to recognise certain types of content and recognise certain attributes of that content. This is done using a ‘machine teaching’ approach, where information professionals and/or subject matter experts explain to the machine the reasoning behind what features in the documents they want the machine to look for.
Project Cortex will provide a ‘Content centre’ within which Information professionals and/or subject matter experts can use machine teaching to build particular machine learning models. These models can be published out to particular SharePoint document libraries. The model can then populate metadata fields for documents uploaded to the library.
It would seem, from what Microsoft are saying about it, that the machine teaching capability that it will play to the strengths of information professionals, because it will use their knowledge of the business logic behind what metadata is needed about what content. The disadvantage of the machine teaching learning model is that it won’t scale corporate wide. You will have to target what areas you want to develop machine learning models for, just like in the on-premise days when you had to target which areas you would design tailored sites and libraries for.
The developments that are driving change in document management
The following four developments are driving change in document management:
- the move of email systems and corporate document management systems to the cloud;
- the emergence of cloud suites (Office 365 and G Suite) that bring both document repositories and messaging systems (email and chat) into one system;
- the development of enterprise social graphs within those suites that map people to the content that they create (and react to) and the topics that they work on;
- the development of machine learning.
These four developments are interdependent. Machine learning is only as good as the data it is trained on. Within a stand alone document management system there is simply not enough activity around documents for a machine learning tool/search tool to work out which documents are relevant to which people. A machine learning tool/search tool is much more powerful when it can draw on a graph of information that includes not just the content of the documents themselves and its metadata, but also the activity around those documents in email systems and IM/Chat systems.
In their on-premise days Microsoft found it extremely difficult to build shared features between Exchange and SharePoint. Now that both applications are on the cloud, both are within Office 365, both share the same API and both share the same enterprise social graph it is much easier for Microsoft to build applications and features that work with both email and SharePoint.
The gaps that project Cortex may not be able to fill
There are four main gaps in the Office 365 metadata/information architecture model:
- There are constraints on how much use the AI can make of information it finds in emails. Delve confines itself to indexing the attachments of email, and does not attempt to use knowledge within messages. Cortex seems to push that envelope further in that it does penetrate into email messages. If an email mentions an entity ( a project, organisation etc.) Cortex will turn the name of that entity in the email into a link to a topic card. However Microsoft states that Cortex will respect access restrictions so that users will only have access to topic cards about topics that are mentioned in content that they have access to.
- Office 365’s strength is in documents and messages, not data. Most of an organisation’s structured data is likely to be held in databases outside of Office 365 and the Microsoft Office Graph does not draw on this knowledge
- The Microsoft graph is geared towards the here and now. It is configured to prioritise recent activity on documents. It is not geared toward providing ongoing findability of documents over time.
- The Microsoft graph is a model that is designed for any organisation. It builds on the commonalities of all organisations (they consist of people who create, edit, receive and share documents and send and receive messages). An organisation with strong information architecture maturity and well established controlled vocabularies in key areas of its business will find that these controlled vocabularies are not utilised by the Microsoft graph. One of the most interesting aspects to watch when Cortex rolls out later this year is the extent to which it integrates with the Managed Metadata Service within SharePoint. What we would really want is a managed metadata service that has strong hooks into Microsoft Graph, so that the Graph can leverage the knowledge encoded in the controlled vocabularies and so that the Managed Metadata Service can leverage the ability of the graph to push out the controlled vocabularies to content via services such as Delve and Cortex.
These gaps provide the space within which records managers, information architects, and the supplier ecosystem in the records management and information architecture space can act in.
Below are what I see as the medium to long term priorities for information professionals (and the information profession) to work on in relation to Office 365:
- Put your enterprise into your enterprise social graph. The Microsoft Graph in your Office 365 is yours. It is your data, and sits in your tenant. There is an API to it. You can get at the content. What we want is a marriage between the metadata in your enterprise and the enterprise social graph that has emerged in the Microsoft graph on your tenant. We need a tooo would enable us to hold control vocabularies (or bring in master data lists held in other systems), link them to each other and hook them into the Microsoft Graph so that the documents and people of the organisation get linked into those metadata vocabularies
- Make the enterprise social graph persist through time If the Microsoft social graph is needed in order for Office 365 to be findable now, then it will still be needed to find and understand that content in five or ten years time. The question is how can it serve as an ongoing metadata resource when it is geared up only to act as a way of surfacing content relevant to the here and now? This challenge has both digital preservation and information architecture aspects. The digital preservation aspects concern the question of what parts of the graph we need to preserve and how we preserve them. The information architecture aspects concern what contextual information we need alongside the graph, and how we enable any application built on top of the graph to keep current the security trimming of the results it returns. Could we for example have some sort of succession linkages, so that successors-in-post can automatically access the same documents as their predecessors (unless personal sensitivity labels/flags had been applied)?
- Make emails more accessible Delve and Project Cortex have come up with ingenious ways of unlocking some of the store of knowledge cooped up in email accounts without breaking the expectation that each individual has that their email account is accessible only by themselves (or rather only by themselves and their corporate compliance team). Delve does it by confining itself to attachments. Project Cortex does it by confining itself to items of fact. But this does not alter the fundamental problem that the business correspondence of most individuals is locked inside an aggregation (their email account) that is only accessible for day to day purposes to the individual account owner. This is acting as a barrier to day to day information sharing and to succession planning. There is nothing fundamentally wrong in having correspondence grouped by individual sender/recipient. People can be mapped to roles and to topics/projects etc. However the truth is that an email account is too wide an aggregation to apply a precise access permission to. What we need is the ability to assign items of correspondence within an email account to the particular topics/projects/cases/matter or relationship that the item relates to, so that a more suitable access permission can be applied to these sub-groupings. This seems an obvious use of AI.
So here is my wish list from the supplier ecosystem around Office 365
- a tool that lets you keep your controlled vocabularies, link them each other, and link them to the Microsoft graph (or a clear methodology of how to use the Managed Metadata service to do this):
- a digital preservation tool, or a digital preservation methodology, for preserving (and enriching) those parts of the Microsoft graph needed for the ongoing understanding of content across Office 365;
- a machine learning tool that within each email account assigns emails to different topics/matters and allows the email account holder, once they have built up trust in the classification, to share access with a colleague (or their successor in post) to emails assigned to a particular topic/matter.
Sources and further reading/watching/listening
At the time of writing Project Cortex is on private preview. What information is available about it comes from presentations, podcasts, blogposts and webinars given by Microsoft.
On 14 January 2020 the monthly SharePoint Developer/Engineering update community call consisted of a a 45 minute webinar from Naomi Moneypenny (Director of Content Services and Insights ) on Project Cortex. A You Tube video of the call is available at https://www.youtube.com/watch?v=e0NAo6DjisU. The video includes discussion of:
- the ways that administrators can manage security and permissions around Cortex (from 15 minutes)
- the machine teaching and the form processing capabilities (from 19 minutes)
- the interaction of Cortex with the Managed Metadata Service (from 26 minutes).
The philosophy behind machine teaching is discussed in this fascinating podcast from Microsoft Research with Dr Patrice Simard (recorded May 2019) https://www.microsoft.com/en-us/research/blog/machine-teaching-with-dr-patrice-simard/
The following resources provide some background to graphs:
- In November 2018 Fredric Landqvist wrote this blogpost comparing the Microsoft Graph to the knowledge graphs/ontologies that taxonomists seek to build https://findwise.com/blog/beyond-office-365-knowledge-graphs-microsoft-graph-ai/
- This post gives an introduction to the data science behind enterprise social graphs/knowledge graphs, and shows the connection between graphs and machine learning. https://towardsdatascience.com/graph-theory-and-deep-learning-know-hows-6556b0e9891b

Excellent overview James.
Hi James
Some follow up comments to your very interesting post.
In 2010 I published a post titled ‘A Semantic Office’ (https://andrewwarland.wordpress.com/2010/01/23/a-semantic-office/) in which I considered how the then Semantic Web concepts might be applied to XML-based documents in Office 2007 and Open Office. In many respects, the Office Graph is this concept finally coming to light, taking advantage of all the back-end XML-based content that sits across Office 365.
You noted that ‘Most of an organisation’s structured data is likely to be held in databases outside of Office 365 and the Microsoft Office Graph does not draw on this knowledge’. We found that PowerBI has some amazing capability to bring this content together in visual form – including pointing it at content in network file shares.
For reference, the URL for the Graph Explorer is https://developer.microsoft.com/en-us/graph/graph-explorer
You noted that ‘the business correspondence of most individuals is locked inside an aggregation (their email account) that is only accessible for day to day purposes to the individual account owner.’ And ‘What we need is the ability to assign items of correspondence within an email account to the particular topics / projects / cases /matter or relationship that the item relates to, so that a more suitable access permission can be applied to these sub-groupings.’
Recently, an organisation I work with noted that emails (not just attachments) were appearing in Delve and in the ‘Activity’ web part of their SharePoint site. On further inspection, we realised that these emails were coming from the Office 365 Group mailbox that they all belonged to.
This, in turn, highlighted the value of using those O365 Group mailboxes instead of personal (inaccessible) mailboxes for specific correspondence. A bit like a shared mailbox but with all the additional functionality of a SharePoint site and a Team. With some planning, many parts of the organisation may actually be better off moving away from personal mailboxes to O365 Group-based mailboxes for business-related emails. I wrote about that idea here:
https://andrewwarland.wordpress.com/2020/03/07/using-office-365-groups-to-manage-some-records-in-context/
Individual one-to-one emails will continue to exist, but anything that could be part of a Team email ‘conversation’ should be in the Group’s mailbox. Interestingly, the biggest problem most will face with this is the fact that end-users don’t like to ‘work out loud’, they prefer to keep their email thoughts to themselves.
All I want is for the system whatever it is – is to self document. Any emails regarding the issue are sent and received from the work space that contains the project data I am working with. I don’t want to have to file and save, assign metadata, etc. I want to do the task at hand – I’m too busy working.
The tech should be like a virtual secretary who does the records management. Otherwise, we should go back to having actual secretaries – perhaps there is one team member whose role is to manage the records?
Personally, I’m fed up with the tools driving how we work rather than us using the tools. For goodness sake any social media app records my activity, when, what… I’ve done.
You know one of best example I saw was a team using a listserv and posting to that work done, changes etc., to the network. Self documenting, etc.
We are using tech digitally – but we are still stuck applying paper base records management principles.
Need better approaches – tech is designed around how people actually work.