My PhD thesis was published yesterday. You can view it/download it from the Loughborough University digital repository here.
The thesis provides a reassessment of records management theory. It evaluates rival records management approaches to email, sets out a new model of how organisational record systems work, and makes predictions on the likely impact of AI on records management practice.
My thanks for their excellent support and advice go to my supervisory team: Prof Tom Jackson, Prof Graham Matthews and Dr Clare Ravenwood (all Loughborough University) and Michael Appleby (The UK National Archives).
My thanks also go to The UK National Archives for funding and co-supervising the research.
Here is an overview of the contents of the thesis:
Chapter 1 introduces the study, and sets out its aim, which is to arrive at a model of how an organisational recordkeeping system works that:
is compatible with Frank Upward’s records continuum model of how recordkeeping processes work across a society;
reflects a realist understanding of how systems (social programmes) work in the social world;
takes account of learnings from the experience with email systems, and with corporate multi-purpose systems more generally, over the quarter century prior to the time of the study;
is equally applicable for analysing organisational recordkeeping before and after the digital revolution, and before and after a potential AI revolution.
Chapter 2 seeks to explain the distinctive features of the realist perspective on reality, on knowledge, and on scientific progress. It describes how Ray Pawson and others developed a realist perspective on how social programmes work, and developed realist methodologies for investigating social programmes. It explains the implications of taking a realist perspective when looking at how recordkeeping systems work and describes how realism informed the logic of inquiry of this study.
Chapter 3 introduces Frank Upward’s records continuum model, perhaps the most flexible and widely accepted current model of how recordkeeping processes work across a society. It describes the roots of the model in Minkowski’s geometry of Einstein’s spacetime. The chapter draws on both Upward’s model and Minkowski’s spacetime geometry to produce an initial eight step model of the implementation chain of an organisation’s record system. This initial model is used through the study as a means of comparing different theoretical and practical approaches to recordkeeping.
Chapter 4 uses the Einstein-Minkowski light cone view of spacetime as a lens to look at both
natural world record systems; and
pre-industrial social world record systems (using the Medieval English royal administration as an example).
The chapter seeks to establish:
the essential features of recordkeeping systems;
the features of our universe that makes it hospitable to recordkeeping systems;
the ways in which social world record systems are similar to, and differ from, natural world record systems.
Chapter 5 explores the features of recordkeeping systems in the large scale bureaucracies of twentieth century industrial and post-industrial (but pre-digital) administrations. It seeks to identify how such administrations went about balancing the new imperatives of efficiency and precision in their recordkeeping systems whilst endeavouring to preserve the reliability and predictability that had been key features of natural world record systems and of pre- industrial record systems. It looks at how the tensions between these imperatives play out in theoretical differences between:
Jenkinson’s view (expressed in the 1920s) that the original order of records should be respected;
Schellenberg’s view (expressed in the 1950s) that records should be organised by business function;
Scott’s view (expressed in the 1960s) that there is scope for records to be organised in a variety of different ways so long as the context of a set of records is captured and preserved.
The chapter offers an explanation of why it was that, despite these divergent theories, the period between the end of the second world war and the coming of email was a relatively stable period in recordkeeping practice within the administrations of large democracies. characterised more by consensus than contention.
Chapter 6 explores the impact on recordkeeping of the widespread adoption of email as a general digital communications tool at the end of the twentieth century. It sets out the key features of email systems as both communications tools and recordkeeping systems, and how those features exposed fault lines in recordkeeping theory and practice.
Chapter 7 seeks to identify the key points of contention that arose in records management theory and practice in the 1990s.
It does so through an examination of:
a major legal dispute over the management of US presidential and federal government email;
theoretical disputes over what constitutes a record system, and when an item becomes a record.
Chapter 8 seeks to identify the key points of contention that arose in recordkeeping theory and practice in the 2000s and 2010s. It does so through an examination of:
market competition between electronic document and records management (EDRM) systems designed expressly for recordkeeping, and other types of collaboration system, up to and including the move of corporate multi-purpose applications to the cloud;
the policy differences between two rival approaches towards the management of the email of public authorities: namely the approach of moving important emails out of email accounts; and the (Capstone) approach of assigning email accounts to short, medium or long term retention bands depending on the relative importance of the role occupied by the email account holder.
The chapter identifies seven key points of contention in the underpinning beliefs between the two main policy approaches to email. These seven points of contention are analysed in the three following chapters.
Chapter 9 seeks to adjudicate on those points of contention between rival policy approaches towards email that relate to theoretical questions, namely:
the question of when an email becomes a record;
the question of whether an email system is likely to function as a record system;
the question of whether or not the aggregation of records by business activity constitutes the optimum order for records.
It also adjudicates on the question of whether or not a significant portion of the correspondence within an individual’s email account is likely to be needed as a record.
Chapter 10 seeks to adjudicate on the points of contention that relate to the question of whether or not it is possible for an originating organisation to persuade end-users to move business email out of their email accounts.
Chapter 11 seeks to adjudicate on the point of contention that relates to the question of whether or not email accounts are manageable through time as record aggregations.
Chapter 12 seeks to adjudicate on the point of contention that relates to the question of whether or not it could be compatible with European data protection principles for an originating organisation to select some individual email accounts for permanent preservation.
Chapter 13 develops and sets out a model of the trade-offs involved in the design of a record system. The purpose of the model is to help a policy maker, practitioner or regulator to make an informed choice as to which of two imperfect approaches to records management is preferable in any given set of circumstances for any given set of stakeholders.
Chapter 14 uses both the record system trade-offs model presented in chapter 13, and the adjudications on points of contention presented in chapters 9 to 12, to arrive at an evaluation of the rival policy approaches to email. The chapter also:
proposes a formulation of the circumstances in which it is possible to design a record system that works for all stakeholders; and the circumstances in which it is not possible to design a record system that will meet the needs of all stakeholders;
makes an assessment of the implications of the record system trade off model developed in this study, and the evaluation of the policy approaches towards email carried out in this study, for three key records management principles: namely those of respect for the original order of records; the superior efficiency of aggregation by business activity; and the separation of the organisation of records from the context of records.
Chapter 15 describes how this study went about ‘zooming in’ Upward’s record continuum model of how recordkeeping processes work across an entire society to produce a new model of how recordkeeping processes work within a single organisation. It shows how the new model (the ‘record system matrix’) was created by combining the core ideas of Upward’s diagram with the ideas of Pawson on how social programmes work, and of Bearman on how recordkeeping transactions work. The model itself is presented in Chapter 16.
Chapter 16 presents the record system matrix that was developed in the course of this study. The matrix consists of a sixteen-step implementation chain of how a record system works within an organisation embedded in a recordkeeping society. The sixteen steps are presented in a four by four matrix that shows how four elements of a record system (the need to provide an interface to the system, the need to protect records, the need to organise records and the need to apply rules to records) manifest themselves across four phases of a record system (the policy and frameworks phase, the configuration phase, the recordkeeping transaction phase and the management of records phase).
Chapter 17 uses email as a testing ground to explore the practical implications for recordkeeping of the development of ever more powerful forms of artificial intelligence (AI). It makes predictions as to whether AI models for recordkeeping purposes are more likely to be developed by originating organisations themselves, or by the cloud suite providers that provide most organisations in the English speaking world with email systems at the time of this study. It looks at the implications of the relationship between tenant organisations and cloud suite providers for:
the explainability of any changes to retention rules to email correspondence made on the basis of the judgement of algorithmic models;
end-user consent to any changes to access permissions on email made on the basis of the judgement of algorithmic models.
Chapter 18 investigates the theoretical and policy implications of the development of ever more powerful forms of artificial intelligence and of their application for recordkeeping purposes to email. It sets out two thought experiments and uses them as a basis to:
make predictions as which of the main policy approaches towards email is likely to make a safer and better starting point for the application of artificial intelligence models for recordkeeping purposes;
assess whether or not the original aggregation of email correspondence into email accounts (and by extension the principle of respect for the original order of records) will continue to be important once organisations acquire the ability to re-aggregate records at any point in their lifecycle.
Chapter 19 sets out the conclusions of this study with regard to its three objectives, which were to:
clarify, reframe and resolve key tensions in recordkeeping theory;
evaluate rival recordkeeping approaches towards email;
construct a model of how an organisational recordkeeping system works against which any viable approach to recordkeeping could be mapped.
It provides some reflections on the novelty of this study, and some methodological reflections on the use of thought experiments. It also explores a key opportunity for further research arising from this study, namely the opportunity to develop a science of record systems that covers both social world and natural world record systems.
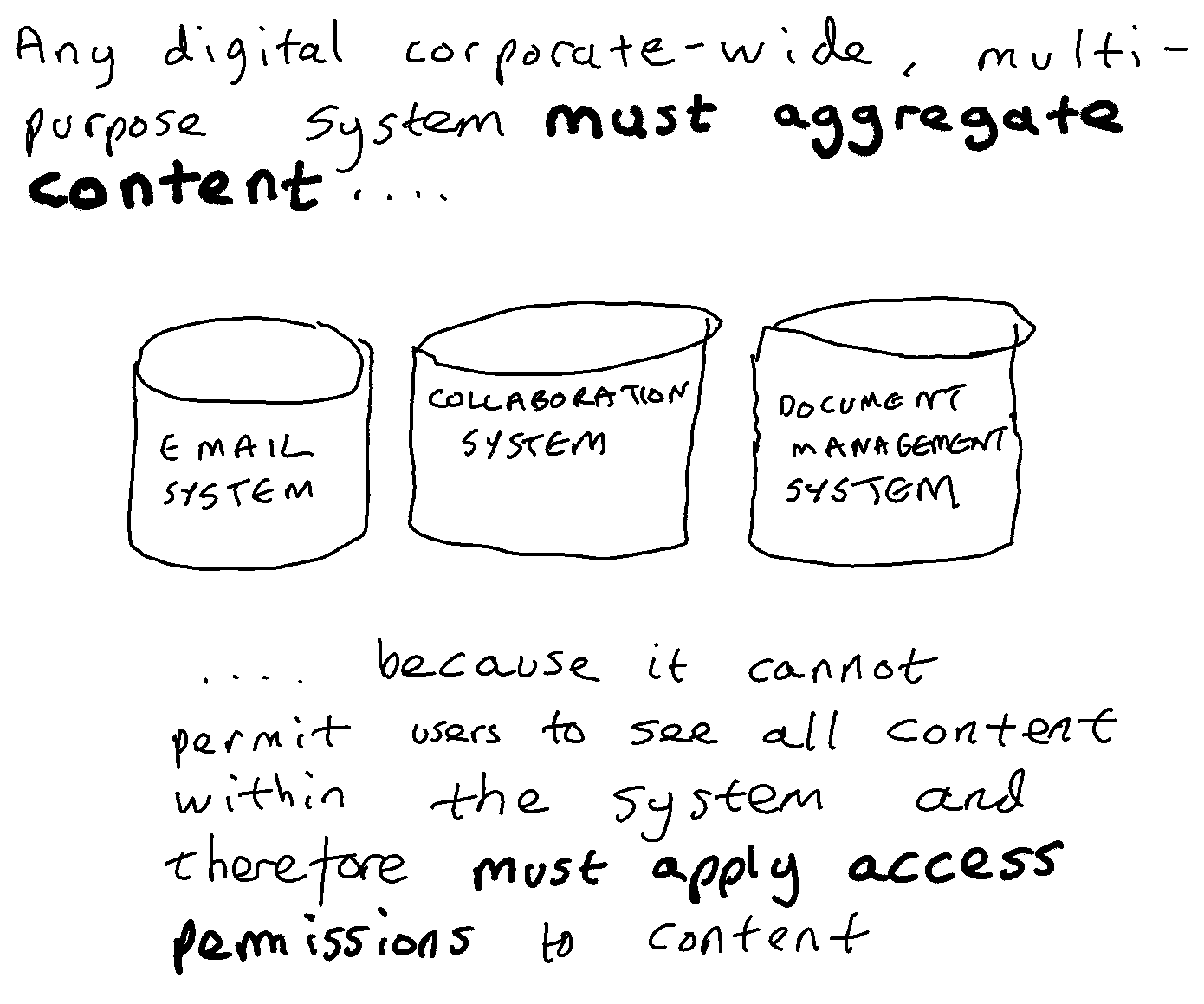
The Information and Records Management Society’s Microsoft 365 Customer Advisory Board Working Group provides a channel through which the records management community can work up feature requests to pass to Microsoft in an effort to influence and inform the company’s future roadmap for the product.
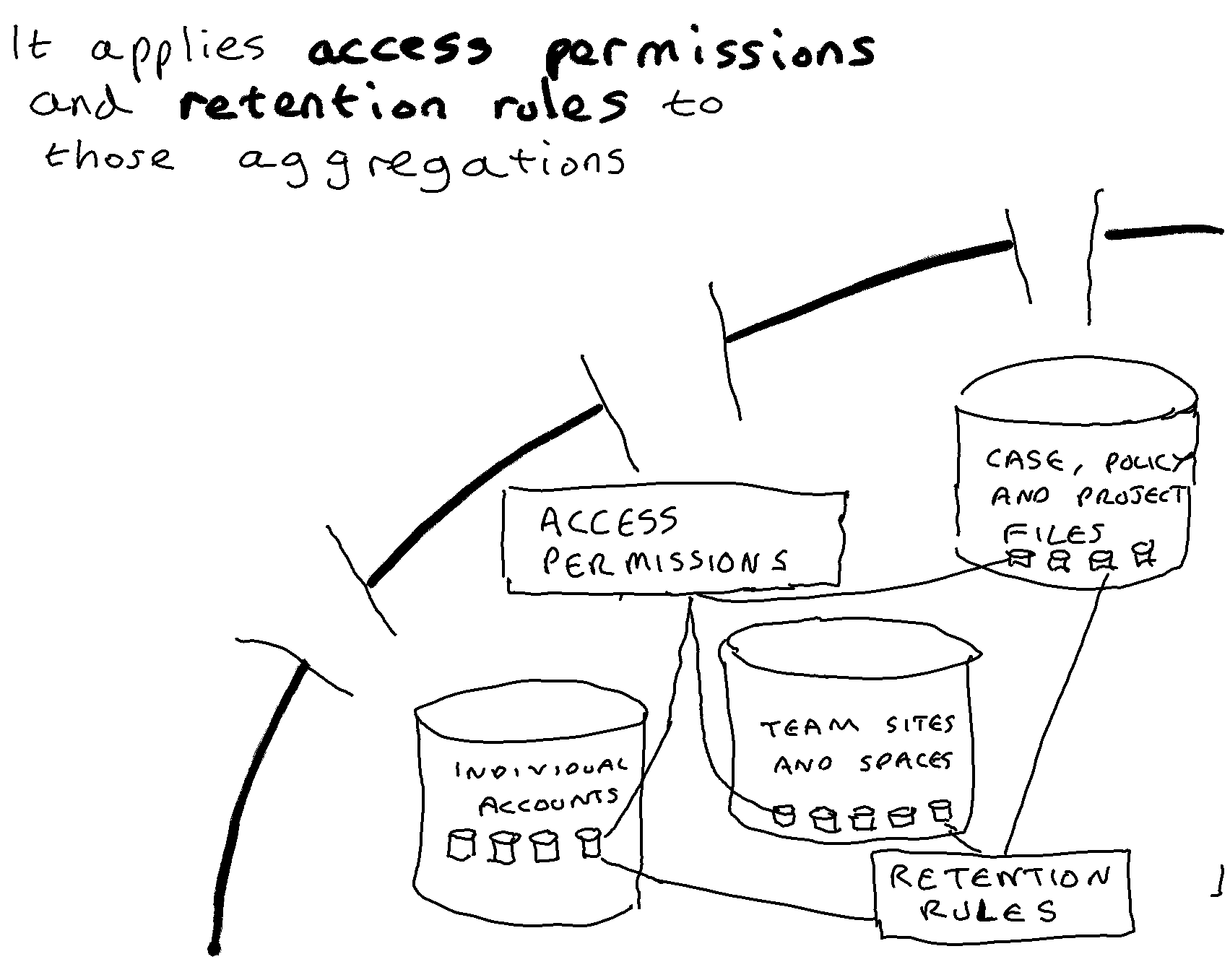
In 2023 the Working Group passed two sets of feature requests to Microsoft, and I reproduce one of them in this post. It is a set of feature requests that aims to make it easier for an organisation to apply a role-based approach to records retention within Microsoft 365.
About role-based retention
Role-based retention has emerged from the Capstone approach to email, developed by the US National Archives and Records Administration (NARA) in 2013.
The working definition of role-based retention used in this set of requirements is that it is an approach to applying retention rules in which:
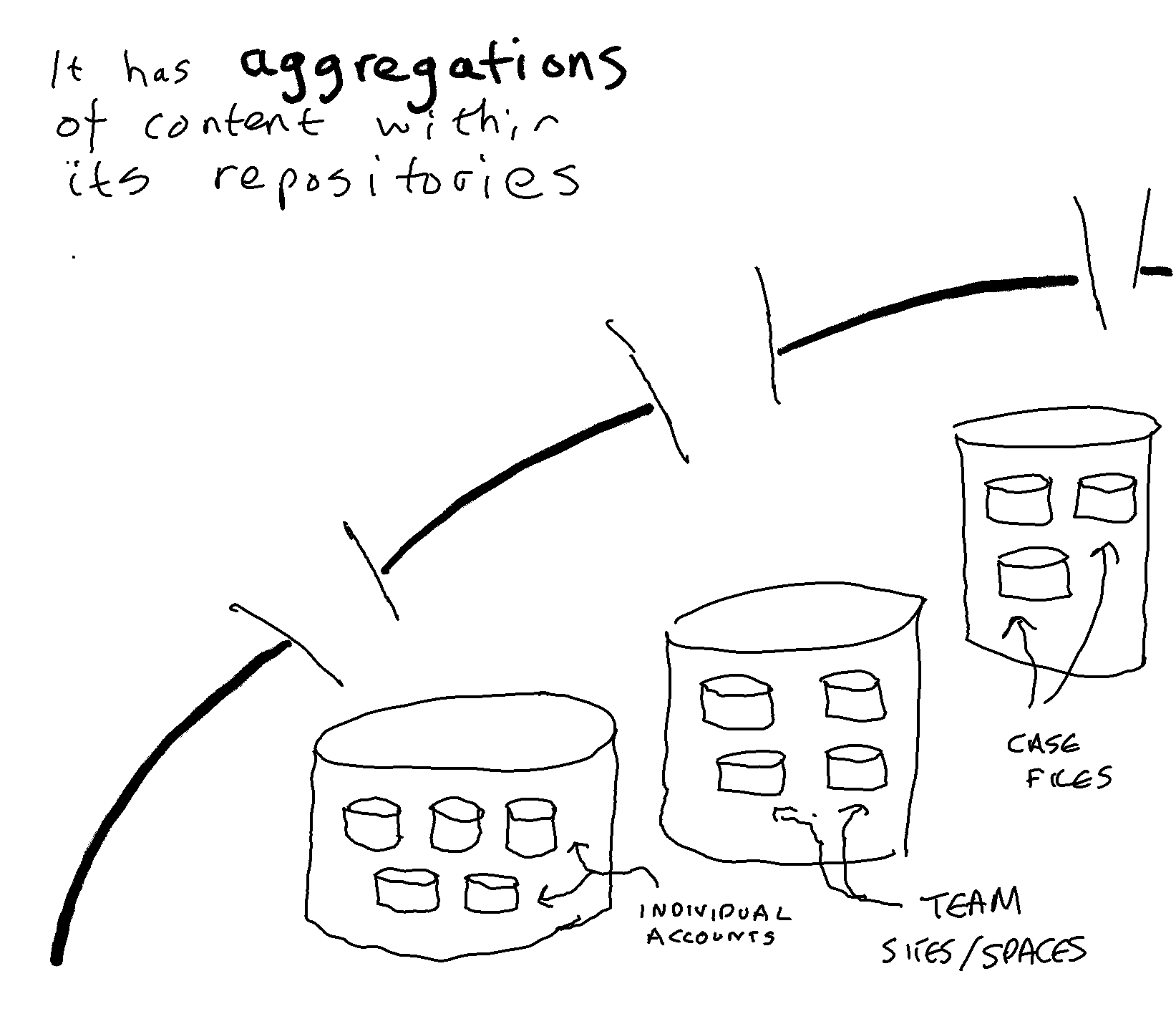
Individual accounts are assigned to a short, medium or long term retention rule depending upon the relative importance of the role of the individual to whom they belong;
Team sites and spaces are assigned to a short, medium or long term retention rule depending on the relative importance of the role of the team to whom they belong.
Like any approach to retention, role-based retention has strengths and weaknesses.
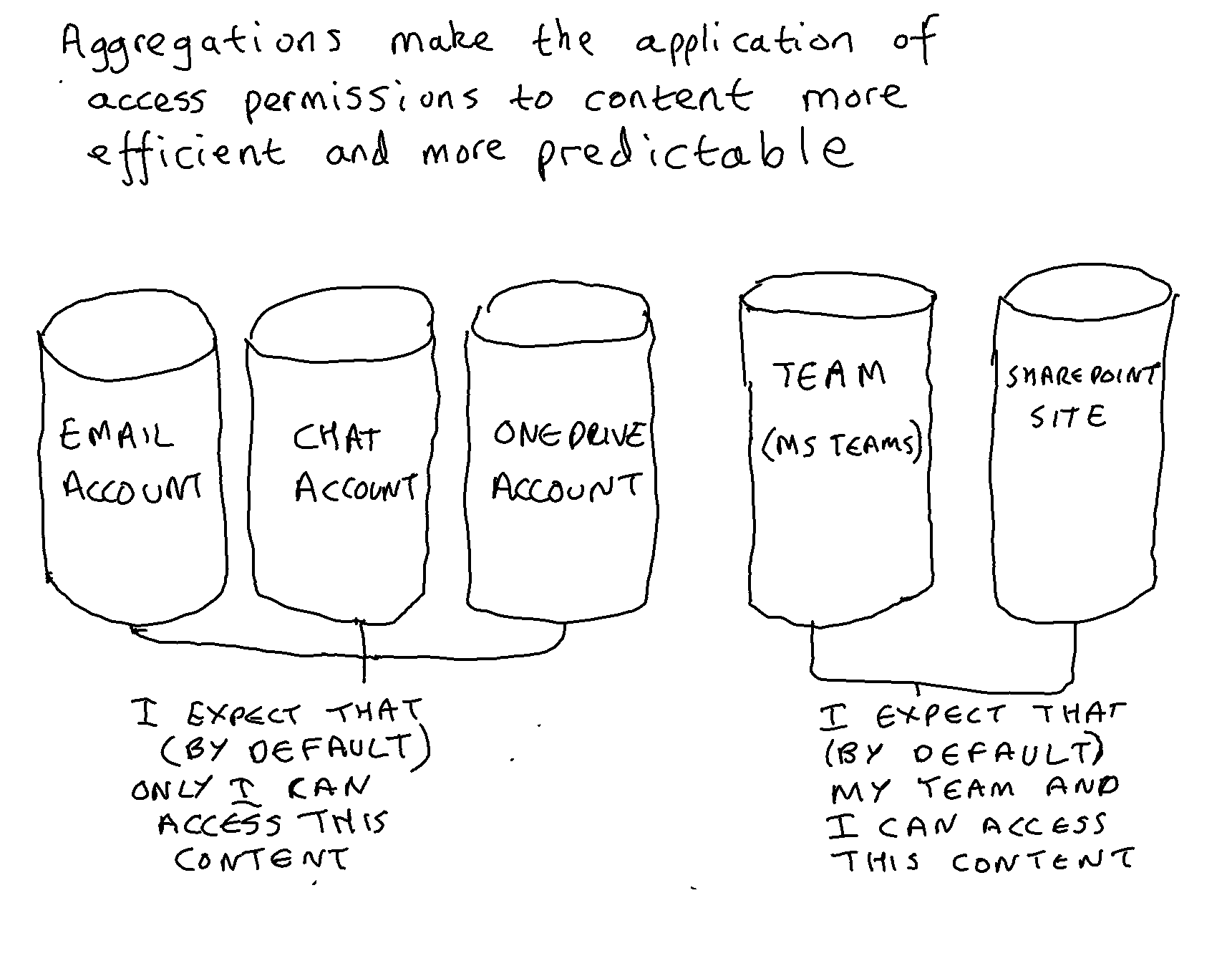
Its main strength is that it uses the existing way that content is aggregated within the communication and collaboration applications of a cloud suite such as Microsoft 365;
Its main weakness is that those aggregations (individual accounts and team sites/spaces) tend to cover a broad range of activities. Individual accounts may contain trivial, social and personal material alongside business content.
About the AI models specified in the set of requirements
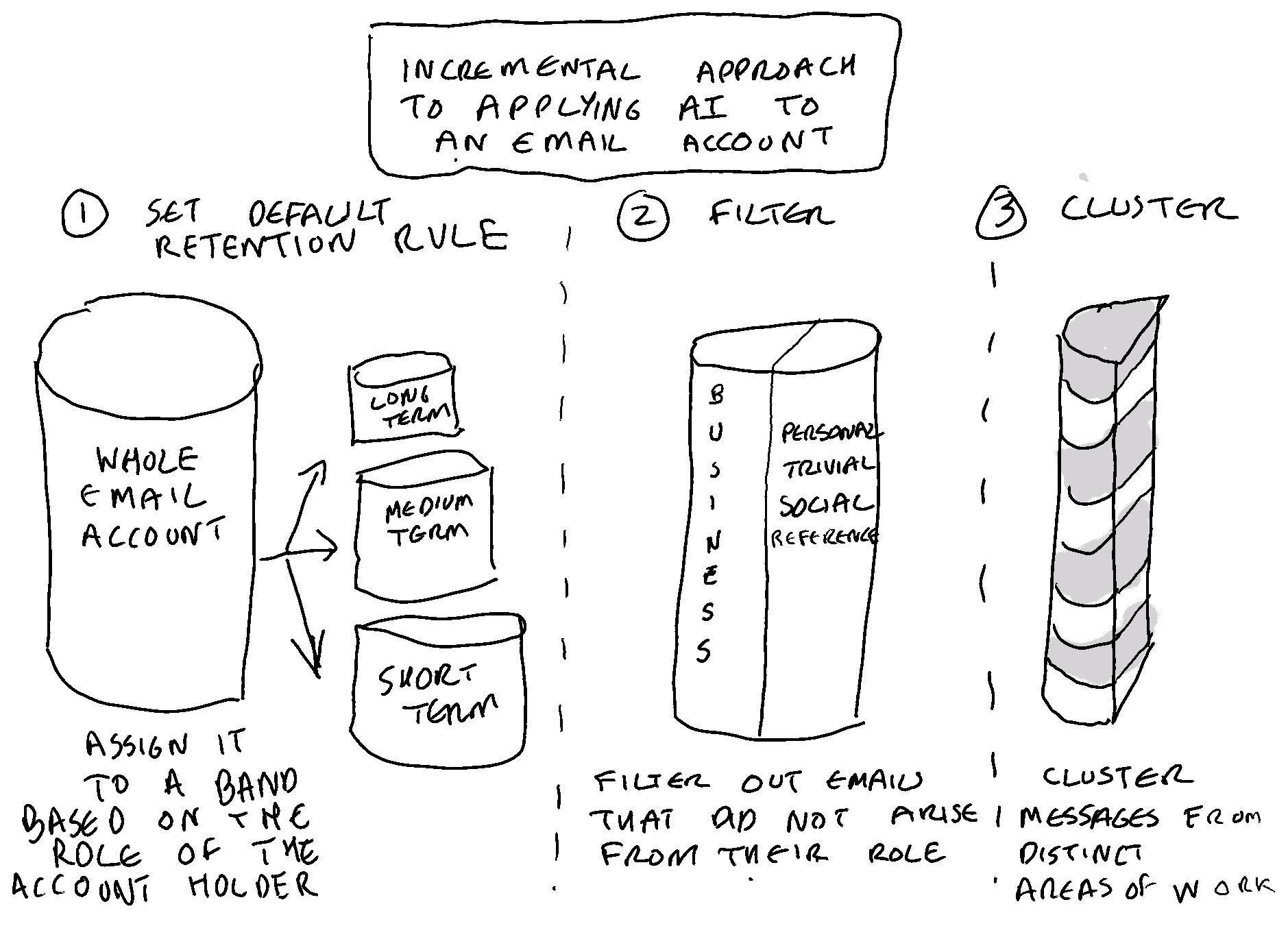
The set of requirements set out below aims to build on the strengths and mitigate the weaknesses of the role-based retention approach. It does so by requesting AI models that work to:
Identify trivial, personal, and social items within individual accounts that have no need to be protected by retention policies;
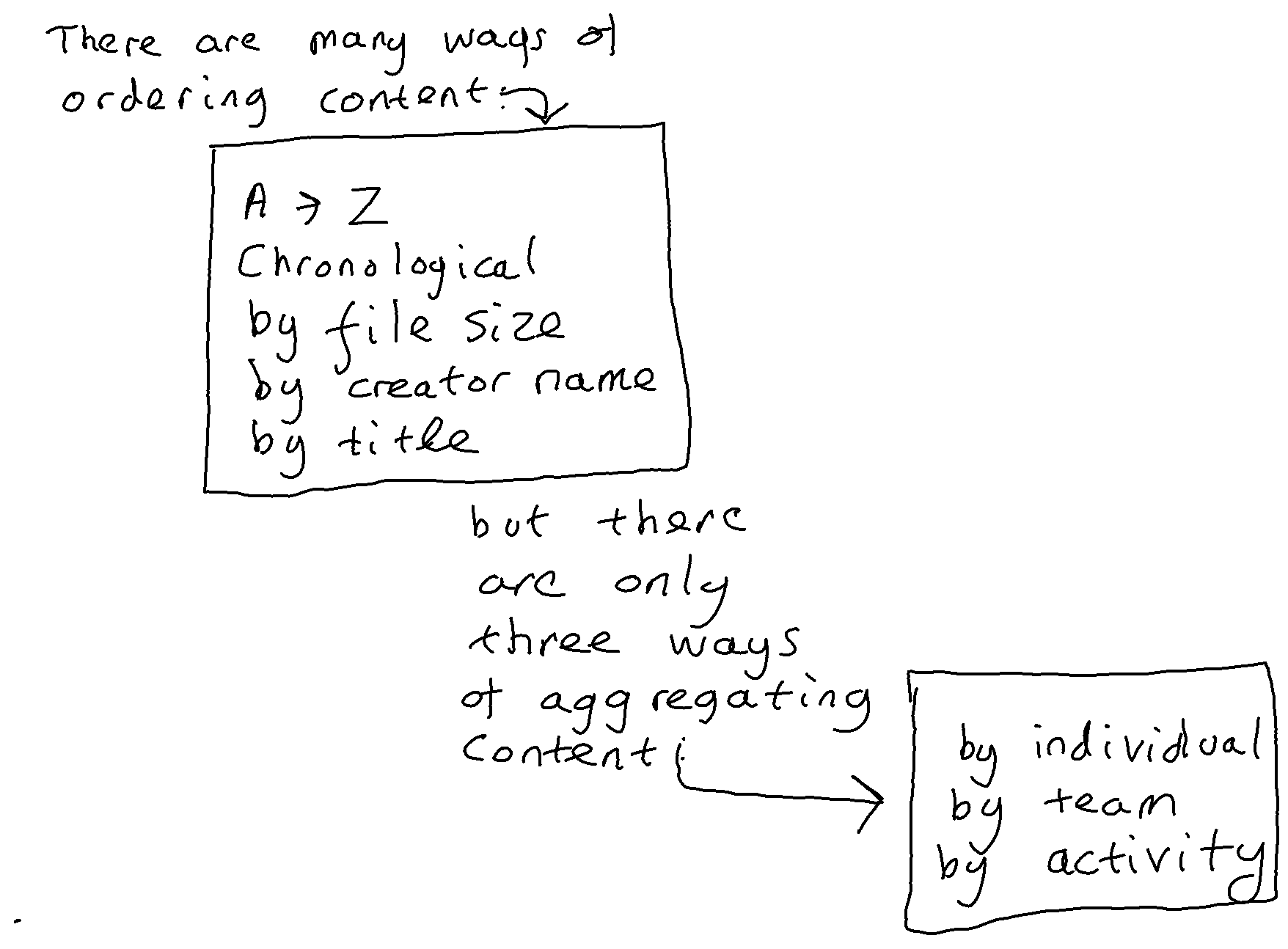
Cluster together (via a common tag) material within an individual account that arises from the same business activity.
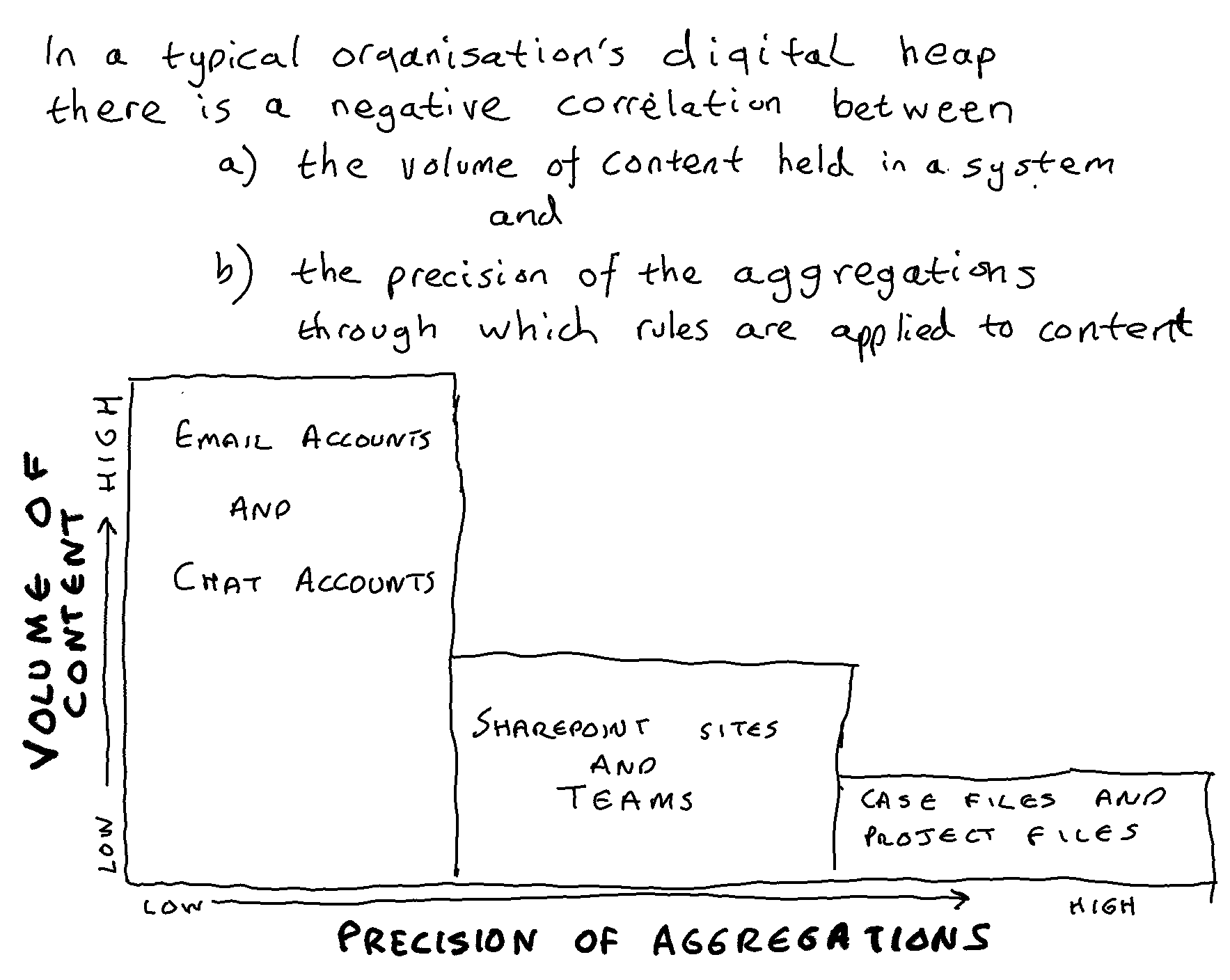
It is likely that social, trivial and personal content will manifest itself in different ways, and have different give-away features, in the different applications of the Microsoft 365 suite. The aggregations in the suite likely to have the most such material are individual accounts within Exchange/Outlook, OneDrive, and Teams Chat. The set of requirements therefore specifies a different model for each of these applications. This gives Microsoft the option of asking the different product groups responsible for these applications to each develop an AI model to identify social, trivial and personal material within individual accounts within that application.
Similarly it is individual accounts that are most likely to benefit from a facility to cluster content arising from the same type of business activity. Again the features of content arising from a similar activity are likely to manifest themselves differently in each different application, so a separate requirement has been arrived at for Exchange/Outlook, for Teams Chat and for OneDrive.
About this set of requirements
What follows is a set of requirements that I drafted, in the context of my work at the UK Central Digital and Data Office, and in discussion with colleagues in the UK National Archives (TNA), the US National Archives and Records Administration (NARA), and the Public Record Office of Victoria (PROV).
The list of requirements reproduced below comes with two caveats:
It does not constitute a standard. Role based retention is one approach to records retention. Other approaches to retention exist.
This is a set of feature requests to a technology company. It does not constitute advice, guidance or recommendations to organisations who use Microsoft 365. Organisations need to decide for themselves which approach to retention to apply to which applications within Microsoft 365, on the basis of their business context and on how those applications are used by their staff.
The set of requirements covers the main workloads of Microsoft 365: Exchange/Outlook (email); SharePoint and OneDrive; Teams and Teams Chat. It attempts to answer the question as to what features and AI models would best support the application of a role-based retention policy in each of these applications/workloads. In practice those organisations that apply a role based retention policy are likely to pick and choose which applications they will apply it to. The presence of requirements for functionality to support role-based retention within a particular application/workload should not be interpreted as a recommendation that organisations apply the approach within the workload – that is a decision for each organisation.
The remainder of this post reproduces the set of requirements that was submitted to Microsoft by the IRMS Microsoft 365 CAB working group.
0.Introduction
0.1 About role-based records retention
The role-based approach to records retention is an attempt to generalise out the Capstone approach to email so that it has the potential to be applicable across any system/application that aggregates content by individual or team. The Capstone approach to email was developed by the US National Archives and Records Administration (NARA) in 2013.
A role-based approach to retention assigns individual and/or team based aggregations to a short, medium or long term retention band on the basis of the relative importance of the role of the individual or team that own it.
Role-based retention is one approach to records retention. Other approaches to retention exist. This requirements list does not attempt to recommend or mandate the approach, rather it attempts to list the features and algorithmic models that would make it possible for an organisation, if it so wished, to apply the approach in one, two, several or all of the main workloads of Microsoft 365.
0.2 About this requirements list
This document was developed by the UK Central Digital and Data Office (CDDO), in conversation with the UK National Archives (TNA), the US National Archives and Records Administration (NARA), and the Public Record Office Victoria (PROV). It was developed with a view to feed into discussions of the Information and Records Management Society (IRMS) IM Tech group, and of the group’s working group for the M365 Customer Advisory Board that is run by Microsoft with the IRMS.
This set of requirements seeks to:
Increase understanding of the role-based approach to retention and what it entails in practice;
Prompt debate about how role-based retention can best be supported inside Microsoft 365;
Set out the features and algorithmic models that would support an organisation in applying role-based retention across the major applications within M365;
Provide a basis for advocacy and dialogue with Microsoft and its ecosystem.
However, this set of requirements:
Does not represent the policy approach of any actual organisation;
Is not intended to express the policy position of any of the contributors to this document;
Does not constitute records management advice to any organisation.
1. Retention bands
One way of streamlining the deployment of a role-based retention approach is to assign each individual (and each team or working group) to a retention band. This is in order to enable each individual account (and/or each team site) to inherit the retention rule applying to the band that the individual (or team) has been assigned to.
Requirements
1.1
Provision of the ability for an administrator to set up three or more retention bands, each with a default retention rule.
1.2a
Provision of the ability for an administrator to allocate any, several or every individual end-user to one of the retention bands.
1.2b
Provision of the ability for an administrator to allocate any, several or every organisational unit/working group to one of the retention bands.
1.3
Provision of the ability for an administrator to access a central record of which individuals and which organisational units have been allocated to which retention band (and between what dates).
1.4
Provision of the ability for an administrator to move an individual from one band to another if they take on a new role which merits a different retention band.
1.5
Provision of a mechanism whereby the change of an individual from one retention band to another (for example after they take on a new role with a very different level of responsibility) results in any content created or received by them in any of their individual accounts from that point in time onwards receiving the default retention rule inherited from their new band.
1.6
Provision of the ability for an individual end-user to access information about what retention band they have been assigned to, and about what retention band the organisational unit(s) they belong to has been assigned to.
1.7
Provision of the ability for an administrator to configure the dynamic assignment of individuals to retention bands on the basis of properties in their Active Directory profile.
2. Allocating default retention policies to containers
Role-based retention involves the assignement of a default retention rule to an aggregation (container) based on the business content within the aggregation. The default rule reflects how long the business content within that aggregation is likely to be of value to the organisation (for operational and/or accountability purposes).
Requirements
2.1
Provision of a mechanism to ensure that each individual account inherits the default retention policy that applies to the band that the individual has been assigned to.
2.2
Ability for an administrator to exempt a particular individual account (or set of individual accounts) from inheriting its retention policy from the band to which the individual has been allocated.
2.3
Provision of a mechanism to ensure that each team collaboration site inherits the default retention policy from the band to which the organisational unit mainly responsible for it has been allocated.
2.4
Provision of the ability for an administrator to exempt a particular collaboration site (or set of collaboration sites) from inheriting its retention policy from the band to which the organisational unit mainly responsible for it has been allocated.
2.5
Provision of a mechanism to ensure that the retention policy inherited by an individual account (see 2.1) or a collaboration space (see 2.3) from the band that it has been assigned to cannot be overriden by any other retention policy applying to the container unless an administrator first allows the inheritance to be broken.
2.6
Provision of the ability for an individual end-user to view the retention policy applying to each of their individual accounts.
2.7
Provision of the ability for an individual end-user to view, for each collaborative site to which they have access, which retention policy applies to that site.
2.8
Provision of the ability for an administrator to view a list of all individual accounts that have been exempted (under 2.2) from inheriting its retention policy from the band that the individual has been allocated to.
2.9
Provision of the ability for an administrator to view a list of all collaborative sites that have been exempted (under 2.4) from inheriting a retention policy from the retention band that the individual/organisational unit mainly responsible for it has been allocated to.
2.10
Provision of the ability for an administrator to prevent any messages within an individual end-user’s Chat account from being acted upon by a retention policy or retention label originating from the account of a party with whom they have been in conversation.
3 Using retention labels to override default policies
An organisation deploying a role-based retention approach would benefit from the capability to identify material within an individual account (or team site) that does not warrant being retained as long as the business content of the individual (or team/working group). They would benefit from the capability to assign a retention period to such content that is shorter than the default for the account/site, and to have that shorter retention period override the default retention policy for the account/site.
Requirements
3.1
Provision of the ability for an administrator to define, for any particular container, any particular set of containers, and/or any particular type of containers, which retention labels (if any) are permitted to override the retention policy applying to that/those containers.
3.2
Provision of the ability for an administrator to prevent a retention label from overriding a retention policy set on a container, or on a defined set of containers, or on a type of containers, unless an administrator had configured the container (as per 3.1) to specifically allow its retention policy to be overriden by that label.
3.3
Provision of the ability for an administrator to configure a container, a set of containers and/or a defined type of containers to permit a particular retention label to always override the default retention policy.
3.4
Provision of the ability for an individual end-user to view, for each of their individual accounts, which retention labels (if any) can override the retention policy applying to the account.
3.5
Provision of the ability for an individual end-user to to view, for each collaborative site to which they have access, which retention labels (if any) can override the retention policy on the site.
4. Identifying trivial content within individual accounts
4.1 Identifying trivial content within email accounts
An organisation applying a role based approach to email would benefit from being able to identify trivial, personal, social and unsolicited emails that do not warrant being retained for as long as the business correspondence within the email account of each individual. For such messages the organisation would benefit from being able to override the default retention policy assigned to the email account with a shorter retention rule applied via a label. Such an organisation might also seek to find a pathway to enable an individual new-to-post (and any generative AI acting on their behalf) to access the business correspondence in their predecessor-in-post’s email account, with the permission of the outgoing post-holder, and without access being provided to any personal or social emails.
Requirements
4.1.1
Provision of the ability for an administrator to automatically assign a retention label to all emails within an email account that the Focused Inbox algorithmic model assigns to the ‘Other’ tab.
4.1.2
Provision of an algorithmic model that runs over content within an email account that has been assigned to the ‘Focused’ tab, and makes a distinction between: – correspondence that has arisen from the individual’s social/personal life; – correspondence that has arisen from the account holder’s business role.
4.1.3
Provision of the ability for an administrator to automatically assign a retention label to all messages identified as social or personal by the algorithmic model specified in 4.1.2.
4.1.4
Provision of the ability for an end-user to correct, reinforce and/or retrain any AI model developed and deployed within their email account in fulfillment of requirement 4.1.2.
4.1.5
Provision of a means for an individual end-user to proactively flag up content within their account that is personal to them.
4.1.6
Provision of a means for an individual end-user to indicate that they are happy for a successor-in-post (and any generative AI model acting on their successor-in-post’s behalf) to see correspondence that has been identified (by the model specified in 4.1.2) as arising from their business role.
4.2 Identifying trivial content within Teams Chat accounts
An organisation applying a role based approach to Teams Chat would benefit from being able to identify conversations that do not warrant being retained for as long as the business conversations within the account of the individual. For such conversations the organisation would also benefit from being able to override the default retention policy assigned to the Chat account with a shorter retention rule applied via a label. Such an organisation might also seek to find a pathway to enable an individual new-to-post (and any Copilot generative AI acting on their behalf) to access the business conversations in their predecessor-in-post’s Chat account, with the permission of the outgoing post-holder, and without access being provided to any personal or social conversations.
Requirements
4.2.1
Provision of a means for an individual end-user to proactively flag conversations within their Teams Chat account that are predominantly personal.
4.2.2
Provision of an algorithmic model that identifies (and tags or labels) conservations that the individual did not contribute to (for example Chat conversations in meetings that an individual attended).
4.2.3
Provision of an algorithmic model that labels each conversation within an individual’s Chat account according to whether it is predominantly a business conversation or predominantly non-business [trivial, business, social or personal].
4.2.4
Provision of a means for an administrator to ensure that conversations within a Chat account that are flagged as not relating to the individual’s business role are assigned a shorter retention period than the default assigned to the account.
4.3 Identifying trivial content within OneDrive accounts
An organisation applying a role-based approach to OneDrive would benefit from being able to identify documents that do not warrant being retained for as long as the business documents created by the individual. Such documents include trivial documents and documents that the individual has not shared with any colleagues. Such an organisation might also seek to find a pathway to enable an individual new-to-post (and any Copilot generative AI acting on their behalf) to access the business documents in their predecessor’s OneDrive account, and that have been shared with their predecessor. This would be dependent on the predecessor-in-post granting permission, and on access being denied to personal, social and trivial documents.
Requirements
4.3.1
Provision of the ability to identify documents/content within the OneDrive account that have not been shared with others (by direct sharing with others, or as attachments to messages, or as Loop components, or by any other means).
4.3.2
Provision of the ability for an administrator to apply a retention rule to documents within a OneDrive account that have not been shared with others that is shorter than the default for the account.
4.3.3
Provision of the ability for an individual end-user to proactively flag up documents that are predominantly social, personal or trivial.
4.3.4
Provision of an algorithmic model that labels each document within a OneDrive account as being predominantly business or as predominantly non-business [trivial, social or personal].
4.3.5
Provision of a means for an administrator to ensure that documents within a OneDrive account that are flagged as not relating to the individual’s business role are assigned a shorter retention period than the default assigned to the account.
5 Clustering correspondence within individual accounts
5.1 Clustering correspondence within individual email accounts
An organisation deploying a role based retention approach to email would stand to benefit from an algorithmic capability to cluster together (for example by assigning a common tag) items of correspondence within an email account that have arisen from the same business activity. This would enable an organisation to apply different retention rules to correspondence arising from different activities of the individual. It would also open up the possibility of an end-user allowing their successor (and any Copilot generative AI working on their successor’s behalf ) to access correspondence from some aspects of their activities (but not others).
Requirements
5.1.0
Provision of an algorithmic model to create clusters within each email account of correspondence that has arisen from a similar business activity. The model would identify messages that arose from similar areas of work and assign them a common tag.
5.1.1
Provision of a means for an end-user to rename a cluster created within their email account.
5.1.2
Provision of a means for an individual end-user to indicate whether a cluster created within their email account by the algorithmic model specified by 5.1.0 was useful (or not) to them.
5.1.3
Provision of a means for an individual end-user to re-assign messages from one cluster within their email account to another.
5.1.4
Provision of a means for an individual end-user to add an item to a cluster within their email account.
5.1.5
Provision of a means for an individual end-user to remove an item from a cluster within their email account.
5.1.6
Provision of a means for an individual end-user to indicate whether they are happy for an administrator to know of the existence of a cluster within their email account.
5.1.7
Provision of a means for an individual end-user to indicate to an administrator whether they are happy for a successor-in-post (and any generative AI model acting on behalf on their successor’s behalf) to access a cluster of correspondence created within their email account.
5.1.8
Provision of a means for an administrator to provide a person new-in-post (and any generative AI model acting on their behalf) access to a cluster of correspondence from their predecessor, providing that their predecessor had confirmed their consent (as specified by 5.1.7).
5.1.9
Provision of a means for an administrator to assign a retention label to a cluster created within an email account by the algorithmic model specified by 5.1.0.
5.2 Clustering correspondence within Teams Chat accounts
An organisation deploying a role based retention approach to Teams Chat would stand to benefit from an algorithmic capability to cluster together (for example by assigning a common tag) conversations within a Chat account that have arisen from the same business activity. This would enable an organisation to apply different retention rules to conversations arising from different activities of the individual. It would also open up the possibility of an end-user allowing their successor-in-post (and any Copilot generative AI working on their behalf) to access conversations from some aspects of their activities (but not others).
Requirements
5.2.0
Provision of an algorithmic model running within each individual Teams Chat account, that could identify conversations that arose from similar areas of work and assign them a common tag or label, to create a ‘cluster’.
5.2.1
Provision of a means for an individual end-user to rename a cluster that was created within their Teams Chat account.
5.2.2
Provision of the means for an individual end-user to indicate whether a cluster created in their Teams Chat account was useful (or not) to them.
5.2.3
Provision of a means for an individual end-user to re-assign conversations within their Teams Chat account from one cluster to another.
5.2.4
Provision of a means for an individual end-user to add a conversation to a cluster in their Teams Chat account .
5.2.5
Provision of a means for an individual to remove a conversation from a cluster in their Teams Chat account.
5.2.6
Provision of a means for an end-user to indicate whether they are happy for an administrator to know of the existence of a cluster within their Teams Chat account and to see the title of that cluster.
5.2.7
Provision of a means for an individual end-user to indicate whether they are happy for a successor in post (and any generative AI model within Microsoft 365 acting on their successor-in-post’s behalfI) to access a cluster of conversations within their Teams Chat account.
5.2.8
Provision of a means for an administrator to allow a successor-in-post (and any generative AI acting on their behalf) to have access to a cluster of conversations from their predecessor, providing that their predecessor had confirmed their consent (as specified by 5.2.7).
5.2.9
Provision of a means for an administrator to assign a retention label to a cluster of conversations created within a Chat account by the algorithmic model specified by 5.2.0.
5.3 Clustering documents within a OneDrive account
An organisation deploying a role based retention approach to OneDrive may stand to benefit from an algorithmic capability to cluster together (for example by assigning a common tag) documents within a One Drive account that have arisen from the same business activity. This would enable an organisation to apply different retention rules to documents arising from different activities of the individual. It would also open up the possibility of an end-user allowing their successor (and any generative AI model working within Microsoft 365 on their successor’s behalf) to access documents from some aspects of their activities (but not others).
Requirements
5.3.0
Provision of an algorithmic model running within each individual OneDrive account, that could identify documents that arose from similar areas of work and assign them a common tag or label, to create a ‘cluster’.
5.3.1
Provision of a means for an individual end-user to rename a cluster within their OneDrive account.
5.3.2
Provision of the means for an individual end-user to indicate whether a cluster within their OneDrive account is useful (or not) to them.
5.3.3
Provision of a means for an individual end-user to re-assign documents within their OneDrive account from one cluster to another.
5.3.4
Provision of a means for an individual end-user to remove a document from a cluster within their OneDrive account.
5.3.5
Number not used.
5.3.6
Provision of a means for an individual end-user to indicate whether they are happy for an administrator to know of the existence of a cluster within their OneDrive account and to see the title of that cluster.
5.3.7
Provision of a means for an individual end-user to indicate whether they are happy for a successor-in-post (and any generative AI model acting on their successor-in-post’s behalf) to see a cluster of documents within the OneDrive account.
5.3.8
Provision of a means for an administrator to allow a successor-in-post (and any generative AI acting on their behalf) to access a cluster of documents from their predecessor, providing that their predecessor had confirmed their consent (see 5.3.7).
5.3.9
Provision of a means for an administrator to assign a retention label to a cluster of documents within a OneDrive account.
6 Preserving the connection between messages and any attachments
6.1 Preserving the connection between Teams Chat messages and any attachments
Where a Chat message is sent with a document attachment, the message forms an important part of the metadata of the document and the document forms an important part of the content of the message. An organisation applying a role-based approach to the retention of Teams Chat messages would need a way to ensure that any message stayed linked to a document attached to it, even if the message and document were stored in separate repositories.
Requirements
6.1.1
Provision of a means of ensuring that there is a persistent connection between chat messages and any documents that were exchanged within them.
6.1.2
Provision of a location for the storage of an individual’s chat correspondence if and when an administrator decided to no longer retain their Exchange email account (whether for reasons of not having to continue to pay the licence fee or other reasons).
6.1.3
Provision of a means for an administrator to treat an individual’s chat conversations and any attachments posted within them as one aggregation for retention purposes. There must be a way of maintaining the link between chat messages (stored in a hidden folder associated an individual’s email account) and any documents exchanged via Teams Chat, even after an individual has left the organisation and even if an organisation has moved the chat correspondence to a new location and/or disabled the email account it was formerly stored in.
6.1.4
Provision of a means of ensuring that, if an individual’s Teams Chat account is subject to a longer retention period than their OneDrive account, then the folder of documents within their OneDrive account that contains documents they have sent via Teams Chat is not destroyed for as long as the Chat account is retained.
6.2 Connection between Teams channel posts and attachments
Where a Teams channel posting contains a document attachment, the post forms an important part of the metadata of the document and the document forms an important part of the content of the post. An organisation applying a role-based approach to the retention of Teams would need a way to ensure that any post stayed linked to a document attached to it, even if the post and document were stored in separate repositories.
Requirements
6.2.1
Provision of a means of ensuring that a persistent connection is maintained between documents (stored in SharePoint) that have been posted through standard channels, private channels and shared channels, and the channels that they were posted through.
6.2.2
Provision of a means of ensuring that if a SharePoint site is hosting documents that have been posted through Teams channels, that the documents are retained for as long as the channel posts are retained.
7 Decoupling the storage of email from licence costs
When an individual leaves post the organisation is likely to wish to decommission their email address, but may need to retain their email correspondence.
Requirements
7.1.1
Provision of a way of deactivating an email account that: – Leaves open the possibility that it will be possible to make parts of the content accessible (with the individual’s permission) to their successor-in-post and their successor-in-post’s generative AI; – Does not incur a licence fee; – Does not require content to be manually moved.
Copilot is Microsoft’s branding for the way they plan to enhance end-user productivity by making generative AI capabilities available in all their offerings, including Microsoft 365. The M365 Copilot is currently in its Early Access phase which means a select group of organisations already have access to it. No date has been fixed for its general availability but Microsoft are unlikely to want to delay it too long.
The impact of generative AI on records management will be felt from the moment an end-user can go to the Copilot Business chat feature within their Teams Chat client within Microsoft 365 and obtain a useful answer to the following prompt:
give me a timeline of all documents and messages arising from insert name of project. Summarise each document and each message thread and provide a link to the sources.
Copilot will search for the answer to such a prompt across all the information that the individual has access to within the tenancy. It will not matter to Copilot where the information is stored. What will matter is the access permissions on that content. Copilot will only return to an end-user information that they already have access to.
From the point at which Copilot returns good answers to this question there is even less incentive for an individual to move messages and documents out of their individual accounts (such as their email account, Chat account and OneDrive account) into shared spaces like SharePoint libraries and Team Channels. They may feel able to use their Copilot to pull together content scattered across different applications and to find content buried in accumulations of email/chat.
Any attempt to shift end-user behaviour to do more work outside of individual accounts or to move content out of individual accounts will face an uphill struggle because Copilot will reinforce rather than challenge the behaviour of working and storing content in individual accounts.
As Copilot gains in strength a key records management task will be to build pathways to ensure continuity of access to business correspondence and documentation held in individual accounts as staff move post or leave employment. A person new-to-post does not have access to content in their predecessor’s individual accounts. Neither will the Copilot acting on their behalf. The Copilot of a person new-to-post will have access to considerably less content than their predecessor did, because it will take time for them to build up accumulations of correspondence and documentation in their individual accounts.
Short term adaptations to the problem of unequal access to information
It is possible to predict some short-term adaptations that teams and individuals may make to address this unequal access to content. For example if an individual is about to leave post, then their manager might ask them to:
run a Business Chat Copilot prompt for each of the main projects/cases/matters they had been dealing with, to get a timeline of documents and messages
run a Business Chat Copilot prompt for each of the key stakeholder relationships that they had been dealing with to get a timeline of documents and messages
make the outputs of the above prompts accessible to their teammates and their successor-in-post.
An individual new-to-post who receives a disappointing response to a Copilot prompt might ask a colleague who has been in post longer (and hence has a longer memory in their individual accounts) to run the same prompt and send them the answer.
A pathway to support continuity of access to business content in individual accounts
The above adaptations are unsatisfactory because they are ad-hoc and haphazard. Records management works better when it is routine and comprehensive. A better approach would be for AI models to run within individual accounts to make distinctions that make it as easy and safe as possible for an end-user to grant access to named individuals (and their successor-in post) to sections of their email/chat/OneDrive content.
In the email environment Microsoft 365 already provides a focused inbox feature that relegates unsolicited emails to a secondary ‘other’ tab. It would be beneficial if that feature could be extended to make a further distinction within ‘focused’ email, that separates out ‘business’ email from ‘personal’ or ‘social’ email. This would enable an organisation to ask individuals if they were willing to grant access to their successor-in-post (and their successor-in-post’s Copilot) to the emails marked as ‘business’.
The more fine-grained the distinctions that AI models can make within individual email accounts the better. If an AI model could make distinctions within the emails marked ‘business’, to cluster together the emails arising from particular pieces of work, then:
it would support end-user productivity (for example by supporting a Copilot prompt focused on one particular cluster) and
it would support pathways for continuity of access by enabling the end-user to grant access for their successor-in-post (and/or a named individual) to emails arising from a specific piece of work, once they were satisfied that the AI model was assigning items to the cluster in a predictable and precise manner.
Note that such a clustering model would not require the organisation to build a records classification. Nor would it require the AI model to learn a records classification. it could be an unsupervised learning model that was able to recognise the features (in terms of commonality of vocabulary, commonality of attachments, and/or commonality of participants to the messages) that meant that certain emails were likely to have arisen from the same piece of work.
Note also that such clusters would not do away with the need or value of having a records classification. An obvious next step would be a capability to allow an end-user and/or an administrator to link particular clusters within their email account to a records classification.
The Microsoft 365 cloud suite is a set of corporate multi-purpose applications:
an email system (Exchange);
a document management system (SharePoint);
a collaboration system (Teams);
an instant messaging application (Teams Chat);
a filesharing application (OneDrive); and
an enterprise social application (Yammer/Viva Engage).
Various common services are wrapped around these applications. These include services that provide means of securing, governing, and searching content held within those applications.
Microsoft will have an implicit strategy as to how the applications within their suite relate to each other, what they envisage them being used for, what they envisage them storing, and how access and retention rules get applied to content created or received within them.
Many of the tenant organisations that use Microsoft 365 will have their own records management strategy. Each such strategy will express the organisation’s choices and preferences about how different digital applications relate to each other, what they should be used for, what should be stored in them, and how access and retention rules get applied in them.
This opens up the possibility that a difference may arise between the records management strategy of a tenant organisation and the broad direction of travel of the Microsoft 365 suite. This raises the question as to the extent to which a tenant organisation’s records management strategy needs to take account of Microsoft’s direction of travel for M365.
The ‘evergreen’ nature of Microsoft 365
Microsoft 365 is an ‘evergreen’ cloud suite. Microsoft introduces a constant stream of new features with the aim of improving the user experience; making users more productive; extending the power of AI models within the suite; and improving the ability of tenants to govern and protect content across the suite. This permanent state of product improvement is essential in order to stay ahead of their competition.
For each set of significant new features introduced by Microsoft into M365 we need to look not just at what those features do, but also at what they say about the direction of travel of M365 as a whole. Each successive new round of features moves M365 further forward along the direction of travel the company has determined for the product. Any difference between a tenant organisation’s records management strategy and Microsoft’s direction of travel will tend therefore to grow over time. Any records management strategy which is significantly different to Microsoft’s direction of travel will, over time, become progressively harder for a tenant organisation to apply within M365.
Let us imagine a tenant organisation that has a high level of information management expertise. Such an organisation might adopt a records management strategy based on:
a preference for an application (such as SharePoint) that they can configure with a sophisticated, hierarchical, metadata-rich information architecture;
a preference for individuals to work in shared spaces (such as Teams channels and SharePoint sites), rather than in individual accounts (such as Teams Chat accounts, Exchange email accounts and OneDrive accounts);
a preference for any important content in Teams Chat, Exchange, or OneDrive to be moved to an appropriate library in the architecture created within SharePoint.
Nothing that Microsoft is going to introduce will make that strategy impossible to pursue. It will remain a defensible approach, and a viable strategy for organisations with very strong information management capabilities. But it is clear that Microsoft’s strategy for M365 is based on a different set of preferences. The overall trend of new features introduced by Microsoft since the birth of the Office 365/M365 suite shows:
a preference for applications (such as Teams and OneDrive) with a flat modular architecture that any organisation can roll out regardless of their level of information management expertise;
neutrality as to whether individuals communicate through individual accounts (such as Teams Chat) or shared spaces (such as Teams Channels);
neutrality as to whether content is stored in SharePoint, OneDrive or Exchange;
a preference for content to remain in the repository used by the application that it was created in.
One discernable element of the direction of travel of M365 is the establishment of Exchange to act not just as an email system, but also as a general repository for messages created in any new application developed within the suite. SharePoint and OneDrive act as the general repositories for documents created in any new application within the suite. MS Teams was the first new application that Microsoft created within Office 365/M365. It was configured so that it does not store any of the messages and documents that go through it:
messages sent through Teams Chat are stored in a hidden folder linked to the email account (in Exchange) of each person participating in the chat. Messages posted to Teams channels are also stored in Exchange, in a hidden folder associated with the shared email account of the M365 Group that is linked with the Team (see this post for more details);
documents sent in Teams Chat messages are stored in the OneDrive account of the sender. Documents posted to Teams channels are stored in a library of the SharePoint site associated with the Team (see this post for more details).
New feature sets in M365
Microsoft are in the process of introducing three potentially important feature sets into M365:
Loop allows an individual to create a collaborative shared resource inside a a message within their individual Teams Chat account or email account, and invite others to contribute to it;
Copilotis the M365 equivalent of ChatGPT. It aims to make an individual more productive by delivering them information relevant to the content they are creating at a particular point in time. The information is sourced from the total set of information accessible to that individual in any application within the suite;
Viva Topicsis an AI model that aims to act as a source of reference within M365 for the organisation. It analyses content stored in SharePoint to identify projects/topics that the organisation is working on. It creates a topic card (akin to an intranet page) for each topic, with a description of the project/topic, links to key resources and names of key contacts. That topic card can be made available to individuals when they encounter mention of the topic (or when they themselves mention the topic) in various applications within M365. Like Copilot it is trimmed for access permissions so an individual is only shown information that is already accessible to them in content within the tenancy.
These three new feature sets have nothing directly to do with records management. They have no direct impact on the access permissions and retention rules that are applied to content. But they do give us an indication of the direction of travel of M365 with regard to the relationship between new M365 functionality and existing M365 repositories, and with regard to how AI models will work in the suite. And that overall direction of travel will act over time, to make some types of records management strategy easier to apply within M365 tenancies than others.
Relationship between new feature sets and existing M365 repositories
Microsoft have set the default storage location for items created with Loop to be the OneDrive account of the individual who created the item. At first sight this decision is surprising. Collaboration is about sharing content and working together, whereas OneDrive is based on individual accounts. But on closer inspection Microsoft has no other choice.
Microsoft can safely assume that almost every individual in almost every tenant will have an email account, a Teams Chat account and a OneDrive account. Microsoft can also assume that every new collaboration object will be initially created by an individual. Microsoft can therefore be sure that every new Loop object will have a logical home in the OneDrive account of the creator. Any proliferation of Loop objects will not result in a proliferation of new aggregations because the OneDrive accounts already exist.
In contrast if Microsoft had wanted Loop content to be stored by default in SharePoint, then they would almost certainly have been forced to spin up a new SharePoint site every time a new Loop object was created for a new combination of users. This is because of the idiosyncrasies of SharePoint’s architecture:
every document in SharePoint needs to live in a library;
every library needs to live in a site;
every site has an owner who has powers over all content in the site;
there is no way of knowing whether any given set of people collaborating on a Loop object are happy for that Loop object to come under the control of that particular site owner.
MS Teams is engineered so that a new SharePoint site is spun up for every new Team created, purely in order to house a document library for the Team in the site. In theory Microsoft could have adopted this model for Loop, with a new SharePoint site being spun up for every loop object, but the short lived nature of the collaborations envisaged for Loop would make this disproportionate and undesirable.
The decision to architect M365 to store messages in Exchange and documents in SharePoint/OneDrive has an important consequence. It is relatively straightforward for Microsoft to architect any major new application or feature set to store content in individual accounts (OneDrive accounts and/or individual Exchange email accounts). It is much more complex for Microsoft to architect the new application/feature set to store content in shared spaces (SharePoint document libraries and/or shared Exchange email accounts). Over the course of time this is likely to lead to an increasing portion of content being stored in individual accounts.
How AI models work in M365
Copilot and Viva Topics are different AI models that stand independently of each other. Copilot dredges information from anywhere within the tenancy that the individual has access to. Viva Topics dredges information from anywhere in SharePoint (or rather those parts of SharePoint that administrators have allowed it to trawl). But they have two key architectural feature in common:
they are both trying to use AI to make an individual more productive by bringing them knowledge specifically relevant to their context;
they both trim their outputs to ensure that every piece of information they present to a particular user is already accessible to them within M365.
We can predict that the more effective the AI models in M365 become, the less it will matter to a user where a particular item of content is stored. What matters is whether they (and by extension their AI models) have permission to view the content. We can also predict that the more effective the AI models become, the less Microsoft will be concerned about which of the M365 repositories content is stored in.
In effect a new type of aggregation has come into existence as a result of the development of these AI models. That aggregation is the set of content within a tenancy to which a particular user has access to. This aggregation is not visible to anyone except the AI models, but the AI models must know its boundaries otherwise they would not be able to trim the information they are providing to individual users as auto-suggestions, topic cards etc.
Let us assume that Copilot will continue to improve over the course of the next two or three years as it achieves greater adoption and as its algorithms are further refined in the light of that adoption. If this proves to be the case, then Copilot will reach a point at which it enables an individual to benefit significantly from the information they have access to within M365. Some of that information will be held in their individual accounts, the rest will be held in the various shared spaces that they have access to.
At a certain point in time that user will leave their post of employment A new individual might be appointed to replace them. The new individual is likely to be given access to the shared spaces that their predecessor had access to, but not to the material in their predecessor’s individual accounts. Consequently there will be a drop-off in effectiveness of Copilot for the new person in post. This drop-off will persist until the new person accumulates, over time, a sufficient breadth of relevant content in their own individual accounts.
In order to flatten out this drop-off there may arise a need to develop ways in which an organisation can safely provide a new person in post (and the AI models working on their behalf) with access to the non-personal content held in the individual accounts of their predecessor. In order for that to happen another AI model may be needed, that works within the individual accounts of a user and identifies personal material that the AI model predicts the user would not want to make accessible to their successor-in-post. It is likely that the only person who could act as the human-in-the-loop to monitor, reinforce and retrain such a model, would be each individual end-user themselves.
Such a model could be seen to be successful if and when it reaches the point at which an individual would be willing to freely grant permission for their successor (and by extension their successor’s AI models) to access the material within their individual accounts that the model had not identified to be personal.
The journal Archival Science has published the latest paper from my doctoral research project into archival policy towards email. The paper is entitled ‘Rival records management models in an era of partial automation’. It is an open access paper and is free to read and to download from here.
The paper argues that:
the adoption of email in the 1990s brought in an era of partial automation. Email systems could automatically file correspondence, but not into a structure/schema of our choosing;
Frank Upward’s records continuum model sees a recordkeeping system as a set of processes that involve the creation, capture, organisation and sharing of records;
in an email system the process by which correspondence is captured is optimal. Correspondence is filed instantly according to very predictable and reliable rules. Metadata values are assigned consistently and accurately;
the structure and metadata schema of a typical email system is sub-optimal. Correspondence is not linked to the business activity it arose from, and business correspondence is not distinguished from personal, trivial, and social correspondence. This causes difficulties with the management and sharing of records (most notably when an individual leaves post and their successor cannot normally be permitted to access the business correspondence within their email account).
A significant proportion of archival and records management thought over the course of the past quarter of a century has gone into trying to specify what constitutes an optimal structure and metadata schema for a records system.
In the era before email, when we did not have the capability to automatically file correspondence, there was a level playing field between different ways of structuring a record system. An organisation had a choice of several ways it could file correspondence (chronologically, alphabetically by correspondent, functionally by business activity). It did not take appreciably more effort for a human to file into any one of these three different structures than into any of the others. It therefore made sense to choose the structure that gives the optimum efficiency in terms of the management and sharing of records through time. This equates to the structure that is most efficient from the point of view of the application of records retention and access rules. Theodore Schellenberg, author of the foundational text on records management, tells us that the most efficient way of organising records is by function and business activity.
The coming of email changed this equation. An email system automatically files all of an organisation’s email correspondence alphabetically and chronologically at the email system level, and all of an individual’s correspondence alphabetically and chronologically at an email account level. There is no longer a level playing field between different ways of structuring a record system. We can automatically and instantly file email correspondence chronologically and alphabetically, but if we want to file it by business activity then that would have to be done manually.
In this era of partial automation we have a paradoxical situation whereby if we were to ask end-users to file email correspondence into an application with an optimal structure/schema (one that organises records by business activity) then we are likely to make the recordkeeping of the organisation less efficient and less reliable. This is because we would be using an unreliable manual process to re-file correspondence that had already been filed automatically and reliably into a sub-optimal structure/schema.
The paper therefore finds a justification within archival theory for approaches that seek to manage correspondence in place within the structure and metadata schema of a native messaging application (for example of an email system) even where that structure/schema is sub-optimal . This justification is valid in circumstances where the native application has automatically and reliably assigned correspondence to that structure/schema, and where the organisation lacks an automatic and reliable means to re-assign correspondence to an alternative (more optimal) structure/schema.